系统设计里面有很多开放问题。解决问题的策略是基于经验不断演进的。
ceph 的 bluestore 有好几种 allocator。其中的 AvlAllocator 基本就是 ZFS 的 df (Dynamic Fit) Block Allocator 的 C++ 移植版。所以要清楚 AvlAllocator,就绕不开 ZFS 的前辈。
那么什么是 df allocator 呢?它和 metaslab 又有什么关系呢?故事要从 slab allocator 说起。
slab allocator
我们知道 allocator 设计需要解决的问题就是在高效分配内存空间的同时最小化碎片。如果我们使用 first-fit 在空闲列表里面找指定大小的空闲块,搜索是快了,但是它可能产生更大的内部碎片。best-fit 虽然看上去很好,而且它会产生很小的内部碎片,这些碎片就像下脚料一样,很难利用了,因此性能其实也不见得就能改进很多。buddy 算法中所有的内存块都按照二的幂向上取整,这样方便搜索和方便回收,和合并伙伴内存块。但是这样也会造成相当的碎片,而且在频繁地内存分配和回收的时候,积极地合并策略也会浪费 CPU cycle。
根据观察,系统里面经常会分配释放特定大小的内存块,比如说一个异步的分布式系统里面可能会分配大量的 mutex 来细粒度地管理它的 inode,每次构造和析构都对应着内存子系统的分配内存和释放内存的操作。有一个解决的办法就是维护一个专门的列表,保存特定大小的 extent。加入刚才说的 mutex 大小是 43 字节,那么我们可能就会用一个列表保存一系列大小为 43 字节的内存块。这样分配和释放这样大小的内存的速度就是 O(1) 的。这种列表根据具体的应用场景可以有好几个,要是 inode 的大小是固定的话,inode 也可以有个专门的列表。但是这样处理也带来了问题,到底应该为这种专用列表分配多少内存呢?还有一个重要的问题,就是内核里面频繁地创建和析构内核对象本身也会耗费大量的 CPU 资源,这种开销甚至比为这些对象分配内存的开销还要高。slab allocator 应运而生。
slab allocator 最初是 Jeff Bonwick 为 Solaris
内核设计的,后来这个算法也用到了 zfs 和其他操作系统里面。slab
算法中的每个 slab,都对应着一类固定大小的对象。比如说 slab#1
就专门服务大小为 14 bytes 的对象,slab#2 对应 23 bytes
对象。在这个基础上,我们还有专门类型的 slab,比如专门提供
inode 的 slab,或者专门提供 mutex 的
slab,它们可以省去初始化和销毁对应类型对象的开销。每个 slab
由一个或多个物理地址连续的内存页构成。slab
从这一系列内存页为给定大小的对象分配内存。“专用列表”的思想其实是一种
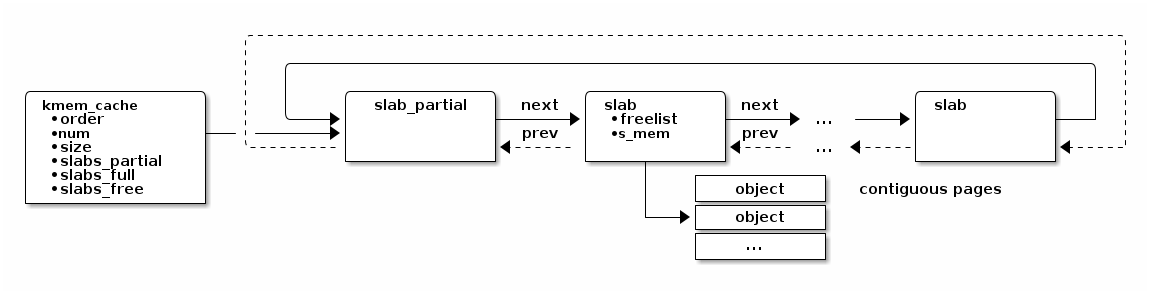
cache,用来缓存特定大小内存块的分配信息。kmem_cache
中的 slab_partial 是一个 slab
的双向链表,其中每个元素都是一个 slab。当某个 slab 所有的
对象都回收的时候,这个 slab 就从
slabs_partial 移动到了
slabs_free 里面去,如果一个 slab
里面所有的页都分配了,那么这个 slab 就会加入
slabs_full。分配内存的时候先从
slabs_partial 里面找,找不到的时候才看
slabs_free。这样分配对象的时候更高效一些。
metaslab allocator
ZFS 作为当初所说的终极文件系统,包揽了从文件系统,卷管理系统,到块设备管理的所有工作。它引入了一个概念叫做 zpool,所以不管是裸设备还是 raid 设备都可以一股脑地扔到这个池子里,交给 ZFS 全权管理。所以 ZFS 的 allocator 要分配一个 extent 有三步:
-
选择设备 (dynamic striping): 目标是让各个设备的空间使用率尽量平均。为了达成这个目标
-
稍微倾向于选择使用率低的设备
-
如果其他因素都差不多,那么用 round-robin。但是粒度需要合适。因为如果粒度大了,比如每次都分个 1GB,那么顺序读写的时候,请求都会往一个设备上招呼,设备间的并发性就没法用上了。但是粒度太小也不好,比如说分了 4KB,就找下一个设备了,那么 buffer 和 cache 的效果就会大打折扣。zfs 发现 512K 是个比较合适的值。
-
ZFS 的数据在刷到数据盘之前,会先以 ZIL (ZFS Intent Log) 的形式先落盘。这有点像 bluestore 里面 journal 的设计。ZFS 希望能通过引入这个 write cache 的机制,让写操作的数据先保存在比较快的设备 (SLOG) 上,之后再刷到目标设备,这样客户请求可以更快地完成。在需要低延迟低大量写数据时,就会使用 round-robin 调度设备,用类似扫射的方式,充分利用多设备的带宽。
-
striping 的策略可以根据数据的类型不同而不同。比如大块的顺序访问,小的随机访问,生命周期比较短的数据,比如刚才说的 ZIL,还有 dnode 这种保存 metadata 的数据。其中 dnode 有些类似普通文件系统里面的 inode。这些都是值得进一步挖掘和研究的地方。
-
如果发现有设备性能不好,就应该尽量不使用它。
-
-
选择 metaslab: 每个设备都被切分成多个的区域,每个区域就是一个 slab。slab 的数量一般在 200 个左右。为什么是 200 个?其实也没有做很多分析。所以这个数字可能不是最优的。metaslab 0 在最靠外的磁道上,metaslab 200 在磁盘最靠里的磁道。每个 metaslab 都有个对应的 space map 用来跟踪 metaslab 的空闲空间。space map 是一个日志,记录着分配和回收的操作。所以分配空间的时候就会在 space map 最后面加一条记录,说明分配了哪个 extent,回收的时候也类似。需要注意的是,如果 space map 还不在内存里面,就需要从硬盘的 space map 日志重建。
-
我们假设磁盘的扇区在磁道上分布基本是均匀的,而磁盘转动的角速度是恒定的。所以在外圈柱面 (cyliner) 的数据分布会比内圈的数据分布更密集,比例就是磁道的半径。LBA 的寻址模式下,地址越低的 LBA 地址,对应的柱面就越靠外面。所以为了访问速度考虑,我们更希望用 LBA 地址更低的 metaslab。
-
-
选择 block: ZFS 确定 metaslab 之后,就会从这个 metaslab 里面分配 block 或者说 extent。它首先从磁盘上读取对应的 space map,然后重放它的分配和回收记录,用来更新内存里面用来表示空闲空间的 b-tree,树里面的节点对应空闲的 extent,树按照 extent 的 offset 排序。有了这个树就可以高效地分配连续的空间。同时它也是一个压缩 space map 的手段。如果分配和回收的操作很多互相抵消了,换句话说,如果树的规模很小,那么 ZFS 会重建硬盘上的 space map,把它更新成内存里面那个更小的版本。space map 的设计有这么几个好处
-
不需要初始化。一开始的时候,树里面只有一个 extent,表示整个设备是空闲的。
-
伸缩性好。无论管理的空间多大,内存里面会缓存 space map 的最后一个 block。这一点是 bitmap 望尘莫及的。
-
性能没有痛点(pathology),即不会因为特定的使用模式造成性能急剧降低。不管是分配和回收的模式怎样,space map 的更新都很迅速。不管是 B-tree 还是 bitmap,在随机回收的时候,对数据结构的更新也是随机的,而且会产生很多写操作。虽然我们可以推迟更新下面的数据结构,把最近释放的 extent 保存在一个列表里面,等到这个列表太大了,再把它排序压缩,写回下面的 B-tree 或 bitmap,以期更好的性能,和写操作的局部性。但是 space map 在这方面基本没有影响,因为它本身就是个 free list。它记录 free 的方式就是写日志。
-
pool 很满或者很空的时候,space map 的都很快。不像 bitmap 在很满的时候搜索空闲块会更花时间。
-
其实还有第四步,如果 metaslab 里面没有能满足的 range,就选择一个新的 metaslab。然是如果根本没有能满足要求的 metaslab,而且也检查过了所有的设备。ZFS 就开始 gang!“gang” 的意思就是把这个大的请求拆解成多个不连续的小的请求,希望它们合起来能满足要求。所谓“gang”也有点三个臭皮匠顶一个诸葛亮的意思。但是这是 allocator 的最后一招了。不到万不得已,allocator 不会 gang,因为这样会产生非常多的碎片。
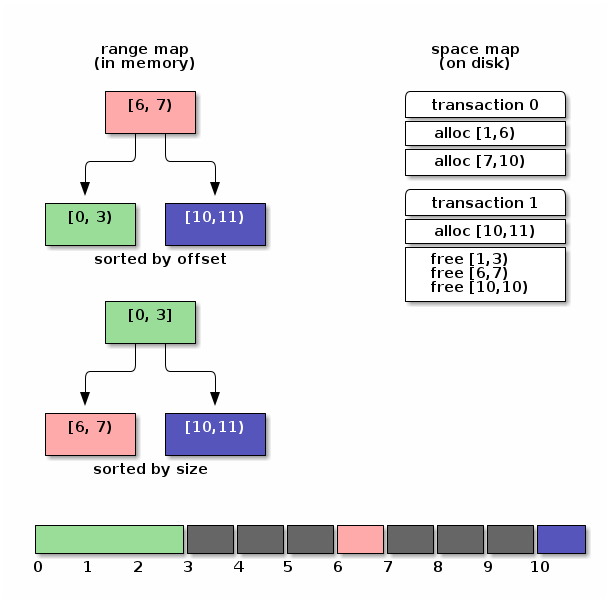
| 早先 ZFS 早期使用 AVL 树来保存 space map,但是后来因为 AVL 树太耗费内存了,每个节点都需要额外用 48 byte 保存 AVL 树需要的信息,每个 extent 都有自己的节点,所以对于海量的小 extent,这样的开销是巨大的。所以 ZFS 后来改用了 b-tree。至于为什么一开始选择 AVL。其实也没有什么特别的考虑,主要是作者在实现 metaslab allocator 的时候,Solaris 内核里面已经有 AVL 树了,所以就用了它。理论上说,红黑树也是可以用的。只要它里面的元素是有序的就行。 |
space map
space map 在内存里面由 ms_tree 和
ms_size_tree 表示。其中 “ms” 是 MetaSlab
的缩写。两者保存的是同样的信息。
-
ms_tree中的空闲空间是按照它们的地址排序的。这样方便合并相邻的 extent。 -
ms_size_tree则是按照大小排序的。这样可以根据需要 extent 的大小来搜索。
在 Paul Dagnelie 的
Metaslab Allocation Performance
里面提到,为了减少内存的压力,甚至可以在
ms_size_tree 里面保存部分的
range。因为对于比较小的 alloc 请求来说,顺着 cursor
找,一般来说很容易在放弃之前找到足够大的 extent。所以只要
ms_tree 里面能找到就够了。让
ms_size_tree 保存比较大的 range,那些 extent
才是比较难找到的。
选择 range/extent/block 的策略
这些策略使用 cursor 记录上次分配的位置,希望下次分配的时候,用 first-fit 的策略从上次分配的位置开始找,希望能紧接着在上次 extent 的后面分配新的空间。这样当大量写入数据的时候,下层的块设备能把这些地址连续的写操作合并起来,达到更好的性能。这对于磁盘是很有效的优化策略,对 SSD 可能也能改进性能。毕竟,谁不喜欢顺序写呢。
CF (Cursor Fit) Allocator
这个算法只用了两个 cursor。
-
根据
ms_size_tree找到最大的一个 metaslab -
让
cursor和cursor_end分别指向 metaslab 的两端 -
每次分配新的空间都往前移动
cursor,直到cursor_end。这表示 slab 里面的空间用完了,这时候就找一个新的 slab。
DF (Dynamic Fit) Allocator
所谓 “dynamic” 是指算法会根据具体情况动态地在 best-fit 和 first-fit 两个算法中选择。这个算法用一个 cursor 指向上次分配 extent 结束的地方。
-
如果 slab 的剩余空间小于设定值,就根据需要 extent 的大小,找够大的就行。
-
如果剩余空间还比较大,为了局部性,首先继续上次结束的地方搜索。搜索的范围由
metaslab_df_max_search限定,如果超过这个大小还找不到,就退化成按照大小搜索。只要找到和需要大小相同或者更大的 extent 就行。
每次分配到 extent,都会推进
ms_lbas[bits_of_alignment] 让它指向新分配
extent 结束的位置。这样相同对齐要求的 extent
就会从相邻的位置分配出来,不过这并不能防止其他对齐大小的
extent 也出现在同一区域中。
NDF (New Dynamic Fit / clump) Allocator
clump,即“扎堆”。其实这个名字更能说明这个算法的用意。它希望主动地为请求的大小选择成倍的更大的空间,预期接下来会出现多个相同大小的请求。
-
先在
ms_tree里面找[cursor, cursor+size)的 extent,如果找到足够大的 extent。就把cursor往前移动size -
找不到的话,就在
ms_size_tree里面先找大小为 2metaslab_ndf_clump_shift 倍size的 range,等找着了,就把cursor指向它,以它作为新的基地,发展成为这种对齐 extent 扎堆的地方。当然,新“基地”的大小是按照当前 slab 的最大空闲空间为上限的。
bluestore 里的 Avl Allocator
AvlAllocator 基本上是 ZFS 的 DF Allocator 较早版本的 C++ 移植。它继续用 AVL tree 来保存 space map。但是不同之处在于,bluestore 里面的 AvlAllocator 并没有 gang 的机制。所以 AvlAllocator 必须自己实现它。