引子
SeaStore 是 Crimson 使用的存储引擎。它的目标是
-
高性能
-
全异步
-
支持 ZNS 和高性能的存储介质比如 PMEM
-
支持异构存储
-
兼容 Ceph 现有的 object store 的语义
可以看出来,SeaStore 很像一个文件系统。
-
文件名就是 object store 里面 object 的 object id
-
文件的内容就是 object 对应的数据
-
文件的 xattr 和各种属性,就类似 object 的 omap 和 xattr
-
当然文件还支持快照,这个和 object 的快照也很相似
-
类似的还有 mount、umount 和 fsck 这类操作
-
和文件系统一样,SeaStore 也有碎片的问题,所以我们也需要 defrag
文件系统的设计可能有好多方面
-
它像数据库: 需要高效地执行查询和修改的操作。对不同性质的访问模式也可以有不同的优化策略。
-
它像 allocator: 需要有效地管理空间。比如说,分配空闲空间,跟踪使用的空间,释放不用了的区域。
-
它也有 cache: 需要利用不同性质的存储介质,比如说利用低延迟的存储作为缓存,而用大容量的存储保存冷数据。
-
它像调度器: 需要在服务前台请求的同时,也能兼顾后台的任务。所谓磨刀不误砍柴工。
所以一篇文章很难讨论到所有的问题。我们先从垃圾收集说起。为什么?因为笔者正好有一本 《垃圾收集》。有点拿着榔头找钉子的意思吧。
Zoned Storage 和 degragmentation
先说说“钉子”。目前 SeaStore 主要针对的存储介质叫 Zoned Namespaces SSD。ZNS flash 和 叠瓦盘(SMR) 都属于 Zoned Storage。后者因为读写性能不彰,消费级市场上大家避之不及。但是如果作为冷存储,性价比还是很高的。要是能在应用层结合性能更好的存储介质一起使用,综合下来性价比可能还会更好。但是它最大的问题在于,不支持原地 (in-place) 修改的,所有的修改操作都通过 copy-on-write 实现。整个磁盘被分成好几个区域 (zone),每个区域都只能添加数据,不能重写已经写入的数据。但要是已经写入的数据被删除了,我们就要回收它们占用的空间。要是需要修改的话,就得复制一份新的。同样,也需要在复制完毕后,回收原来数据占据的磁盘空间。回收的时候,最少必须清除整个 zone。就像用活页笔记本记笔记,每页纸都从头写到尾,如果写坏了,想改一下呢?只能把那一页撕掉,换一张纸重新誊一遍。小块儿的橡皮擦在这里是不能使用的。
为了帮助理解问题,还需要提一下 SSD 的访问模式。一块 SSD 板卡上一般有多块 NAND 存储芯片,这些芯片通过一定数量的 channel 连接到控制器芯片。所以 SSD 最小的并发单元就是就是单块 NAND 芯片,最大的并发数就是 NAND 芯片的数量。因为无法向一块 NAND 芯片同时发送多个请求。存储领域我们喜欢说 LUN (logical unit number),在这里我们也把特定的 NAND 用 LUN 来表示。一个 channel 由多个 LUN 共享。而每个 NAND flash LUN 由高到低分成不同的层级
-
channel. channel 之间不共享资源,可以充分并发。
-
LUN. 连接到相同 channel 的不同 LUN 之间可能会有数据依赖的问题,这一定程度上影响并发。
-
plane: 一个芯片有 2 个 或者 4 个 plane。对某个 page 进行写操作的时候,需要对挂在不同 plane 的相同地址的 page 同时写。换句话说,一个 4k 的 page 事实上是映射到不同 plane 的 page 的。
-
block: 一般是 512 page。它是 flash 擦除操作的最小单位。
-
page: 由四个 sector 构成,加上额外 (out-of-band) 的空间,用来保存映射本身的信息。sector 的大小一般是 4 KB。写操作的的时候,必须按照 page 在 block 里的顺序写。 每个 sector 由多个 cell 构成。而每个 cell 按照芯片的不同存储的比特数量也不一样。比如说 SLC 芯片是一个比特,MLC 是两个比特,TLC 三个,QLC 四个。这里需要解释一下 page pairing 的设计。根据 cell 保存比特的数量,由对应个数的 page 瓜分。换句话说,一个 QLC cell 对应着四个 paired page。只有所有的 page 都写好了,这次写操作才能算完成。所以对于一块有 4 个 plane 的 QLC 来说,每次写操作都必须同时写 4 个 plane,每个 plane 都因为 QLC cell 写操作的单位就是
-
-
-
-
min_bytes_per_write = 4 /* 4 planes, 1 page per plan */ *
4 /* 4 paired page for each cell */ *
4 /* 4 sectors per page */ *
4_KB /* 4KB per sector */
= 256_KB因此,flash 上的物理地址就由 channel, LUN, plane, block, page 和 sector 构成。读的单位是 sector,而写的单位则是 page。
顺便说一下,PMEM 的组织就相对扁平,它直接由多个 sector 构成。
早在 Zoned Storage 出现之前,因为磁盘的机械特性,大家就已经开始思考怎么把随机写转化为顺序写了,以期提高存储系统的性能。很自然的想法就是把 metadata 和 data 作为 log 顺序地写入磁盘。这也是 log-structured filesystem 中 log 的由来。虽然 LSF 解决了随机写的问题,它也带来了随机读的问题。举个例子,我们在磁盘上保存了一个很大的文件,一开始的时候,文件在磁盘上是顺序写入的,所以它的物理地址是连续的。磁盘在顺序读取整个文件的时候不需要很多次寻道,所以 IO 会很快,带宽仅仅受限于磁盘的转速和磁盘接口的传输速度。但是随着时间流逝,用户先后在文件的不同位置作了一些修改。因为这些修改一样,也是作为 log 顺序写入磁盘的,它们的位置和文件原来的位置差得很远了。所以如果要顺序读取文件的话,
-
这个读请求就可能会在逻辑地址翻译成物理地址的时候被拆分成为很多小的读请求,这极大影响了顺序访问的性能。
-
更不用说因为地址映射表大小增长带来的额外开销。
-
如果寻址是按照块对齐的,那么大量的数据片也会造成内部碎片。比如说,如果有的数据只有 7k,要是磁盘的块大小是 4k,那么最后那 3k 很可能就浪费掉了。
-
损害了读写的局部性。让系统没有办法根据局部性进行优化。通常文件的读写都有一些局部性,文件系统可能会在应用要求读取某个文件开始的 4k 的时候,就把开始的 4M 都读进来了。它估计你很可能接下来也会读这 4M,索性我都读进来好了。反正
-
闲着也是闲着
-
这 4M 的物理地址是连续的,所以干脆一起读了
-
F2FS
f2fs 的 GC 算法解决的问题就是找出一个牺牲的 segment,把里面的有效块保存下来,然后回收它。f2fs 的 GC 分为前台和后台。只有当空闲空间不够了,才会执行前台 GC。前台 GC 要求短平快,这样能最小限度地减少用户应用的卡顿。后台 GC 则更关注总体的效能,它是内核线程定期唤醒的时候执行的。请注意,f2fs 其实并不会手动迁移有效块,它在选出要回收的 segment 之后,把其中所有的有效块都读取到内存的 page cache 里面,然后把它们标记成 dirty。这样,内核在清 cache 的时候,就会顺便把这些需要保存的有效块也一并写入新的 segment 了。这样不仅能减轻对前台的压力,也可以把小的写请求合并起来。另外,值得注意的是,f2fs 同时使用六个 log 区域,分别用来保存冷热程度不同的数据。它甚至把数据分为 cold, warn 和 hot 数据。它由三种 block
-
inode block
-
direct node: 用来保存数据块的地址。它的温度就比 indirect node 高。
-
indirect node: 用来保存 node 本身的 id。这个 id 用来定位另外一个 node。
f2fs 修改数据会更新数据块的地址,为了能让 inode 找到新的数据,它需要更新索引数据块的 direct node,因此 direct node 就是温度更高的 block。它的修改更频繁。
f2fs 设计 GC 思路是让牺牲 segment 的代价最小,同时收益最高。评价策略有下面几种。其中 greedy 和 cost-benefit 是很经典的算法。
Greedy
有效块的个数。所以有效块最少的 segment 就是牺牲品。当 GC 在前台运行时,f2fs 就使用 greedy 策略来选择回收的 segment,这样需要读写的有效块数量最小,所以对用户请求的影响也最小。
Cost-Benefit
cost-benefit 算法最早是 The Design and Implementation of a Log-Structured File System 一文中提出的。论文中设计的 Sprite LFS 文件系统当空闲 segment 的数量低于给定阈值(一般是几十)的时候就会开始 GC,直到空闲 segment 的总数超过另外一个阈值(一般取50到100)。理想情况下的分布应该双峰形的,两个大头分别是有效数据很少的 segment 和有效数据很多的 segment。前者是热数据,后者是冷数据。有效数据比例靠近 50% 的 segment 很少。这种分布对于 GC 来说是比较省心的。因为在回收的时候不需要迁移很多数据。但是使用 greedy 算法的模拟实验结果出乎意料,和局部性更低的测试相比,局部性高的测试产生的分布更差:大量的 segment 都聚集在中间。论文里面分析,使用 greedy 算法的话,只有在一个 segment 的有效数据比例在所有 segment 中最低的时候,它才会被选中回收。这样几轮 GC 之后,所有 segment 的有效数据比例都会降到回收阈值以下,甚至用来保存冷数据的 segment 的有效数据比例也是如此。但是冷数据 segment 使用率是比较坚挺的,它下降得比较慢。可以类比一个收藏家用来保存藏品的储藏室,除非收藏家突然改变了喜好,否则藏品是很少变化的。而冷数据本身也是有惯性的。所以,含有冷数据的 segment 即使大量保有无效数据,但是因为其稳定的使用率,不会被选中回收。
根据这个观察,论文认为,cold segment 里面的空闲空间其实比 hot segment 里面的空闲空间更有价值。为什么呢?我们可以反过来看,因为和那些很快被修改得体无完肤的 hot segment 相比,cold segment 中的无效数据很难迅速增长。它在系统里面会保持相对较高的使用率更长的时间,我们不得已只能去不停地回收那些 hot segment。它们就像离村庄很近的耕地,因为比较近,所以大家都会更喜欢耕种它们。而埋藏在 cold segment 里面的空闲空间,就更难回收。这导致 cold segment 的使用率慢慢地降低,但是无法回收。这些顽固的 cold segment 的比例在一个访问局部性比较强的系统中可能会很高。因为在那种访问模式下,cold segment 中的冷数据的地位更难以撼动。请注意,这里说的局部性强指的是,重复修改的数据只占硬盘中所有数据的一小部分,绝大部分数据是不变的。如果局部性差的话,所有数据被修改的概率基本上是均等的。如果 GC 很积极地回收使用率低的 hot segment 的话,这样虽然当时迁移的成本很低,但是迁移之后当时被迁移的有效数据很快就被修改了,成为了新的无效数据。所以与其不断地迁移这种 hot segment,不如把它放一会儿,等养“肥”了,再 GC 不迟。这样反而效果更好,效率更高。那时候的有效数据的比例会更低。打个比方,就像一条运动裤已经有点脏了,另外一件衣服上面只有一个墨点,如果明天还要踢一场球,那么你说今天是洗裤子还是洗衣服呢?要不今天还是先洗衣服,明天就穿这条裤子踢球,等踢完球再洗裤子吧。
为了能让 GC 更积极地回收这些 cold segment,我们必须在政策上倾斜,让 GC 觉得回收 cold segment 是更有利可图的。所以论文里面把 segment 里面的最新的数据的年龄也作为参数一起计算,segment 越老,那么它里面的的空闲空间至少也经历了那么长的时间。我们把它们解放出来的收益就是两者之积。用公式表达就是:
其中
-
u 表示有效块在 section 中所占比例
-
age 表示 section 中所有 segment 中,最近一次修改的时间。这个数字越大,意味着这个 segment 越 "cold"。用这个时间来估计
-
1 - u 表示回收该 section 获得的收益,因为通过这次回收,能得到的空闲空间是 1 - u。
-
1 + u 表示开销。1 表示我们需要读取整个被回收的 segment,u 表示我们需要往另外一个 segment 写入其中 u 那么多的数据。
论文中的模拟实验表示,这样的策略可以使 segment 在使用率上呈现双峰分布或者哑铃状分布。即低使用率的 segment 和高使用率的 segment 都比较多,中间 segement 很少。这样的分布比较适合 GC。如果再能根据冷热数据进行聚类那么 GC 就会更高效。
f2fs 在最初的 cost-benefit 上稍加改进,它用来计算 \(\frac{benefit}{cost}\) 的 age 并不是 segment 里面 section 最大的那个,而是里面所有 section age 的平均值。
def get_cost_benefit_cost(superblock, segment_index):
usable_segs_per_section = superblock.get_usable_segs(segment_index)
start = superblock.seg_per_sec * segment_index
mtime = sum(superblock.seg_entries[i].mtime
for i in range(i + start, usable_segs_per_section))
mtime /= usable_segs_per_section
valid_blocks = superblock.seg_entries[segment_index].valid_blocks
u = valid_blocks / log2(super_block.blocks_per_segment) * 100
age = 100 - 100 * (mtime - superblock.min_mtime) / (superblock.max_mtime - superblock.min_mtime)
return UINT_MAX - ((100 * (100 - u) * age) / (100 + u))用公式表示,
其中
-
age 表示候选的 segment 在所有 segment 中最老的和最年轻的中的位置,按照百分比计算。如果 segment 很久没有修改,是很冷的那个,那么它的值接近 100。
-
cost 表示回收 segment 的收益。如果有效数据的比例越高,那么 cost 的值就越大;mtime 越 大,age 越小,cost 越大。
CAT
Cost Age Times,这个算法基于 cost-benefit,它同时关注 flash block 的 wear leveling 问题。但是 ZNS SSD controller 已经帮我们处理了,所以这里不考虑这类算法。
ATGC
ATGC (Age Threshold based Garbage Collection) 是华为的开发者提出的算法,用来改进 f2fs 的 GC 效果 (effect) 和性能 (efficiency)。分成三步:
-
先选希望回收的 segment,即 source victim:
-
先根据候选 segment 来确定一个阈值,如果 0 表示最年轻的 segment 的年龄,100 表示最老的。如果阈值是 80 的话,那么就候选者就进一步限制在 [80, 100] 这个区间里面。
-
如果 segment 的年龄小于预设定的阈值,那么就不再考虑把它回收。因此可以避免回收太年轻的 segement,这种 segment 往往更新更频繁。
-
在这个更小的范围里面选择有效块最少的 segment。这样可以减少迁移数据,降低迁移的成本。
-
-
再选要写入的 segment,即 destination victim:
-
以源 segment 的年龄为中心,以设置的值为半径,划定一个区间。尽量选择那些年龄和 source 相近的 segment 作为目标。这样他们的更新频率可能更相近,有助于保持冷热数据的分离和聚类。
-
在划定的区域里面,选择有效块最多的 segment。倘若选择有效块最少的 segment,那么最合适的 segment 就是源 segment 了。
-
-
使用 SSR (slack space recycling) 把有效块从从源 segment 迁移到目标 segment。
| f2fs 除了顺序写日志 (normal logging)之外,还能在空间不够的时候往无效的空间直接写 (threaded logging),写进去的日志串起来一样用。这样虽然把顺序写变成了随机写,但是可以避免 GC 带来的卡顿,要是选择的 segment 有很大的空闲空间,也能顺序写一阵。这种随机写的做法就叫做 SSR。 |
ZoneFS
ZoneFS 没有 GC 一说。它里面每个 zone 对应一个文件。如果是
conventional zone,那么目录名字就是 cnv,如果是
sequential zone 的话,目录名字就是
seq。sequential zone
因为需要确保发射的顺序性,所以只支持 DIO。如果 DIO
写的位置不是 wptr 的位置,它干脆返回 EINVAL。
Btrfs
因为我们的目标是支持 flash,而 flash 本质上是不支持原地 (in-place) 修改的,所以所有的修改操作都通过 copy-on-write 实现。这也正是 SeaStore 的设计很大程度上受到了 Btrfs 影响的原因。而且最近 Btrfs 也开始加入对 zoned 设备的支持。
TODO
SPDK FTL
SPDK 的 FTL 中每个 band 相当于 相当于 f2fs 里的 segment,在 GC 的时候,也需要进行评估
class Band:
def prep_write(self):
# ...
self.dev.seq += 1
self.seq = self.dev.seq
@property
def age(self):
return self.dev.seq - self.seq
def calc_merit(self, threshold_valid: Optional[int]) -> float:
if self.usable_blocks == 0:
return 0.0
if threshold_valid:
valid_blocks = self.usable_blocks - threshold_valid
else:
valid_blocks = self.lba_map.num_valid
invalid_blocks = self.usable_blocks - valid_blocks
valid_ratio = invalid_blocks / (valid_blocks + 1)
return valid_ratio * self.age用公式表示
LSM_ZGC
比较原始的 GC 算法可能仅仅关注 zone 里面有效数据的比例,如果一个 zone 里面的有效数据超过一定比例,我们可能就希望保留它,而回收那些充斥着垃圾数据的 zone。LSM_ZGC 一文 提出的 GC 算法希望解决下面几个
问题
-
冷热数据分离。因为将来在进行另一次 GC 的时候,也会根据数据的性质进行选择 zone。如果一个 zone 里面的冷数据或者热数据的比例是压倒性的多数,那么就可以更容易地决定这个 zone 的处理方式。比如说,如果是绝大多数是冷数据,那么可以放心地把数据搬到冷存储上。要是绝大多数是无效数据,那么这个 zone 就是很好的回收对象。反之,如果 zone 的使用率是 50%,那么做 GC 的时候就难以取舍了。
-
GC 的时候,如果被选中回收的 zone 使用率很高,那么保存有效数据的开销会很大。因为典型的 zone 的大小是 256MB 或者 512MB,所以即使允许用户 IO 抢占后台的 GC 任务,GC 对总体性能产生的影响也会很明显。
-
大量 4k 大小读请求和相对大的读请求相比,后者的性能要比前者要好很多。我们假设后者是 8K 到 128K 的IO。原因是,连续地址的读请求可以充分利用 ZNS SSD 内部的并发能力。因为文中说,一个 zone 里面的数据会被分散到不同 channel 连接的 LUN 上,所以读取更大的读操作就能更好地利用同时使用多个 channel 带来的并发性。但是我认为,使用更大的读操作是一种利用 inter-channel 并发的简便的方式。但是这并不等于说,发送多个分散的小的读操作的并发就不好了。这样做的缺点应该是请求的个数更多了。因为处理多个请求产生的开销也因而增加。但是要得到比较好的性能也需要权衡,如果 64MB 的区间里面,有效的数据只有 4K,那么就没有必要坚持读取所有 64MB 的数据了。
方案
按照在文中的设置,一个 zone 大小为 1GB,一个 segment 为 2MB,一个 block 为 4KB。这些设定很大程度上借用了 f2fs 的磁盘布局。为了提高读操作的效率,如果一个 segment 里面有效的 block 个数小于 16,那么就仅仅读取有效数据,否则就读取整个的 segment。
我把这个思路叫做“大浪淘沙”。每个 zone 都处于下面四种状态中的一个。刚落盘的数据在 C0,以 segment 为单位统计,如果某一个 segment 的数据使用次数超过事先设定的阈值 thresholdcold,所有保存在这种 segment 中的有效数据都被收集到 C1C_zone,其他 segment 中的有效数据则悉数放到 C1H_zone 中。等到下一次 GC 的时候,无论是 C1H_zone 还是 C1C_zone 中,只要数据仍然有效,我们就把它们当作冷数据,一起放到 C2_zone。因为他们都经历了两次 GC 试炼,并且存活了下来。论文的作者期望通过这样的筛选机制,能够有效地区分不同生命周期的数据。其中,请注意,在这里,“冷数据”并不是指访问频次很低的数据,而是很少被修改或者删除的数据。它们经得起时间的考验,历久而弥坚。我们常说的 WORM (write once read many) 设备保存的就是冷数据。就是而热数据则是那种很快失效的数据,这种数据经常修改,它们生命周期很短,转瞬即逝,如同朝露一般。可以说,CPU 寄存器里面的数据就是热数据。所以我们在第一次 GC 的时候会借助保存数据的机会,先把冷热数据初步分开。这样如果要找热数据富集的牺牲品 zone 的时候,可以更容易地找到这样的 zone。但是第二次 GC 的时候就不再关注它们的使用频次了,而只是单纯地把第一代的幸存者都收集在一起。它们都被搬运过一次,而且顺利地活到了第二次 GC。所以它们完全有资格升级成“二级冷数据”。论文认为,第一代幸存者的生存周期相似,所以它们的空间局部性很可能也更好。比如说 leveldb 里面,同一个 SSTable 里面数据的访问频次可能不同,但是它们的生命周期是相同的,读写模式也一致。
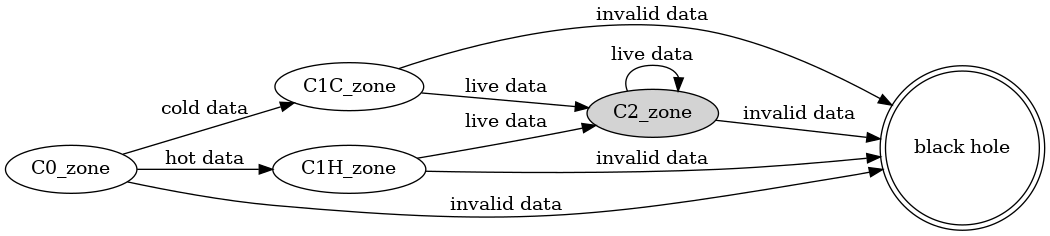
我们还可以更进一步。让经过冷热数据区分后活下来的 C2_zone 数据,升级进入 C3_zone。
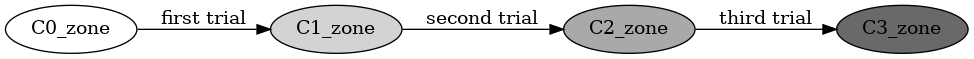
这样通过多次淘汰,我们就可以把数据分出三六九等,有的数据经历了很多次 GC 都巍然不动,有的数据最多只能到 C1H_zone 状态就黯然退场。前者都保存在同一个 zone 里面,所以 GC 的时候就不会因为它们和其他热数据挤在一起,而在腾地方的时候被迫迁移它们,因此就减少了不必要的开销。
GC 的评估
看过这几个算法。试图总结一下怎么评估一个 GC 算法。我们常说,“多快好省”。这里面蕴含着好几个指标。
-
多和好。这里说的是“效用”,即 effectiveness。有时我们也说 efficacy,在这里不区分它们两个。即一个过程的产出情况。
-
多:GC 的一个产出就是释放出来的空间。
-
好:另一个产出,可能是迁移出来数据对数据访问的友好性。比如说,如果迁移出来的数据能根据访问特性很好地聚类,那么局部性可能就会更好。如果把并发性考虑进去,适当地条带 (striping) 化,也能提高大规模顺序读的性能。
-
-
快和省。这里说的是“效率”,即 efficiency。就是说投入怎么样。如果让系统长时间停顿,等待 GC,那么这个投入就比没有卡顿的系统高了。所以说迁移数据的时机和迁移的数据量都和效率息息相关。之前“洗裤子”的例子就是在短期的多和好和长期的快和省之间取得一个平衡。如果只关注短期收益,而忽视长期的总体效益,那么这个算法的总体性能也很难提高。
如果只是考虑“多”和“省”,如果把 GC 看成一个下金蛋的鸡,我们可以用下面的公式计算养鸡的长期利润
对应到 GC,就是
如果让 GC 从一个老化的 (aged) 的存储系统开始,能让系统完成大量的读写删访问,其中写入的数据大大超过系统的空闲空间,那么这个过程中的产生的收益,应该能表征 GC 的性能了。当然,为了理解 GC 的行为产生的效果,也应该佐以数据分布和留存空闲空间大小的统计来评估某一时刻存储系统的健康情况。
整个系统的性能可能还是得看系统在特定负载下的延迟和吞吐量。
SeaStore
因为 SeaStore 当前的目标是支持 ZNS。对它来说,每一张活页纸就是一个 segment。为了理解 SeaStore 怎么做垃圾收集,首先需要知道 SeaStore 里面的 journal 是什么。
Cache
Journal
Journal 就是日志,也就是 log-structured filesystem 里面的 log。在任意时刻,SeaStore 总是指定一个特定的 segment 作为当时写 journal 的专用 segment。
| ZNS 是支持同时打开多个 zone 的。这样让我们可以按照写入数据的不同特性,选择不同的 zone,这样可以避免因为不同生命周期的数据相互交错,导致在 GC 的时候投鼠忌器,难以权衡。但是 SeaStore 现在为了简单起见,还没有利用这个特性。 |
SegmentCleaner
GC 的时机
-
mount 的时候,会扫描 journal 映射的地址空间。这确定了空闲空间的大小,借这个机会,就会看看是不是应该运行 GC。
-
在 IO 事务提交完成时。这时,事务产生的 journal 会减少可用空间。所以也可能需要进行 GC。
先定义几个 ratio:
-
reclaimable ratio: 可回收空间和无效空间之比。
-
可回收空间指的是非可用空间除去被有效数据占用的,剩下的那部分。
-
非可用空间就是总空间减去可用空间。
-
-
available ratio: 即可用空间和总空间的比例。可用空间是下面几项之和
-
空闲 segment 的总大小。也就是空闲 segment 的个数 * segment 的大小
-
当前 segment 的剩余空间。正在用来记 journal 的 segment 就是所谓的“当前” segment。
-
GC 扫描的进度。SegmentCleaner 在 GC 时候会逐一扫描 journal 的所有记录块,它认为扫描过的块都是恢复“自由身”了的可用空间。
-
GC 的条件,只要满足下面的条件之一,就触发 GC
-
空闲空间不够了。需要同时满足下面的条件,才能称为空间不够
-
available_ratio<available_ratio_gc_max -
reclaimable_ratio>reclaim_ratio_gc_threshhold
-
GC 的手段
在上面提到的 GC 时机,seastore 会判断是否满足 GC
的条件,当条件满足的时候,就触发 GC,这时
Segment::gc_reclaim_space() 会扫描以往
journal 分离其中的有效数据,把它们作为 transaction
写到新的 journal
中去。为了避免长时间地阻塞客户端请求,每次扫描的空间大小由
reclaim_bytes_stride 限制,而且我们维护着一个
cursor
记录着上次扫描结束的位置。每次扫描都从上次结束的地方继续。
extents, self.scan_cursor =
journal.scan_extents(victim_segment.body,
start=self.scan_cursor,
step=self.config.reclaim_bytes_stride)
txn = Transaction()
for extent in extents
if not extent.alive:
continue
txn.rewrite_extent(extent)
if self.scan_cursor.is_complete:
txn.release_segment(self.scan_cursor.segment)
self.txn_mgr.submit_transaction(txn)GC 的问题
从改进 GC 效率和性能的角度出发,可以从这么几个方面改进
-
记录数据在产生、访问和修改删除过程中产生的统计信息。
-
跟踪有效数据和无效数据。能迅速地枚举一个 segment 中所有的有效数据。
-
辨别冷热数据。这个需求是上一个的强化形式。即能保存数据块被修改的时间。如果数据经历多次 GC 并存活至今,那么也需要能记录它被 GC 的次数及其年龄。
-
按照数据在应用层面的属性重排或者聚类,提高读写性能。比如说,如果一个对象被分成多个块,那么这些块的物理地址最好也是连续的。
-
-
按照数据的特性分开保存
-
前提是能同时写多个 journal。
-
在选择目标 segment 的时候,LSM_ZGC 和 f2fs 的 ATGC 都主张把类似的数据通过一定的特征进行聚类。
-
-
更有效地迁移有效数据。
-
读的模式:LSM_ZGC 提供了一个思路,让我们有选择地大批量地顺序读,而不总是仅仅读取有效数据。
-