当 C++ 遇上 SPDK。
这两天在学习 SPDK。对于存储软件的开发者来说,它是很好的基础设施。但是这种把回调函数和 context 作为参数,传给异步调用的模式让我有一朝返回解放前的感觉。联想到 Rust 和 Python 语言中的 async/await 语法,再加上两年 seastar 的开发者加入的 coroutine 支持,作为 C++ 程序员不得不重新审视一下,我们是不是也能用新的语法,把异步的 SPDK C++ 程序写得更赏心悦目,易于维护呢?Seastar 作为 C++ 异步编程框架中不可忽视的一员,同时提供了 future/promise 和 C++20 的异步编程模型,如果加上 SPDK 肯定会如虎添翼,成为一个更好的平台。
Seasetar 中的 DPDK
先看看 Seastar 是怎么集成 DPDK 的吧。
在 smp::get_options_description() 里面,为 DPDK
的 --huge-dir 注册了 "hugepages" 的命令行选项。
在 smp::configure() 里面,CPU 核的设置
allocation 经过几次转换,还是作为命令行,传给了
rte_eal_init():
-
dpdk::eal::init()-
rte_eal_init() -
在每个 RTE 核上运行之前交给
create_thread()的 lambda。这个 lambda 暂且叫做reactor_run吧。
-
其中,reactor_run 负责初始化 reactor
线程,和执行调度到的任务:
-
设置线程名字
-
分配自己的 hugepage
-
分配 io queue
-
设置 smp message queue
-
reactor::do_run()-
注册所有的 poller。请注意,poller 在各自的构造函数里面,新建一个 task。它们用 task 来把自己加到
reactor._pollers里面去。poller 可以用来定期等待消息,并处理消息。比如:-
smp_poller用来接收其他 reactor 发来的消息 -
aio 或者 epoll 等到的消息
-
reactor::signals检查 POSIX signal,并调用 signal handler -
低精度的 timer
-
-
成批执行 task。Seastar 允许开发者把一组任务 一起执行。
-
轮询所有的 poller
-
根据是否有遗存的工作决定是否进入休眠模式
-
SPDK
初始化
这里通过分析 SPDK
的初始化过程,关注它的设置,以及调度方式,希望更好地设计
Seastar 和 SPDK 沟通的方式,比如如何初始化,如何和 SPDK
传递消息。SPDK 关心的设置是 DPDK
rte_eal_init() 的超集,除了 DPDK
的相关设置,它还有很多 SPDK 特有的设置
spdk_env_opts ,比如
-
no_pci -
num_pci_addr
每个 SPDK app 都需要执行 spdk_app_start():
-
app_setup_env(spdk_app_opts)-
spdk_env_init(spdk_env_opts)-
rte_eal_init(argc, argv): 参数是根据spdk_env_opts构造的。 -
PCI 相关的初始化
-
-
-
spdk_reactors_init()-
spdk_mempool_create(): 分配内存池 -
为每个核初始化 reactor,设置下面的设施
-
event ring buffer
-
event fd
-
-
-
新建一个
app_thread,并把bootstrap_fn调度到该 thread 上执行-
bootstrap_fn()-
解析给出的 json 文件,里面包含一系列子系统的配置
-
初始化 RPC 服务
-
连接 RPC 服务,挨个加载子系统
-
-
-
spdk_reactors_start(): 在每个 reactor 上执行reactor_run
reactor_run
在 reactor_run 中:
-
批量地处理
reactor→events -
调用所有 spdk_thread 的 poller
-
批量处理
thread→messages -
依次调用
thread→active_pollers -
依次调用
thread→timed_pollers
-
请注意,spdk 会利用 poller
实现定时器和定期执行执行操作的功能。后者把 reactor 作为
worker thread,执行非阻塞的常规任务。比如
vdev_worker 和
vdev_mgmt_worker。这个用法和 Seastar 的
reactor::io_queue_submission_pollfn 相似。但是
Seastar 目前没有把注册 poller 的功能作为公开的 API
提供出来。如果把这个 poll 的任务定义成
task,在退出之前再次调度它自己,那么这种实现可能会降低
Seastar 任务调度的性能。因为在这个 poller
注销之前,它重复地新建和销毁任务,并把任务加入和移出 reactor
的任务列表。这会浪费很多 CPU cycle。
Seastar 框架下 SPDK 的线程
这里结合 Seastar 框架,通过对比两者的线程模型。进一步探索一些可能的实现方式,我们可能会需要回答下面的问题,然后分别解决。
-
如何管理多个用户层面的任务
-
如何发起一个异步调用
-
如何知道一个异步调用完成了
-
如何传递消息
-
不同 core 是直接如何通信的。
-
不同任务之间是直接如何通信的。
-
每个 core 都有自己的 MPSC (multiple producer single consumer) 消息队列,用于接收发给自己的消息。和 Seastar smp 调用对应的逻辑对应着看,可以发现
-
spdk_event_call()等价于seastar::smp::submit_to() -
event_queue_run_batch()等价于smp::poll_queues()
前面解释 reactor_run 的逻辑的时候提到一个概念叫做
spdk_thread。它是 SPDK 中的用户线程。不同的
spdk_thread
之间通过接受方线程的消息队列来互相通信。用户线程消息队列的类型和
core 的消息队列类型和大小相同。spdk_thread_send_msg()
是用来往特定线程发送消息的。值得注意的是,SPDK
内部很多地方都使用了 spdk_thread,比如 bdev
模块就把 spdk_bdev_io 和一个
spdk_thread 相对应,实现 IO
的序列化。所以我们如果要让 Seastar 能更好的支持 SPDK
的话,就必须实现这个机制。
对于 SPDK 来说,spdk_thread
是一个工作协程,用来承载不同的业务。很多时候被用来并序列化并执行各种操作,它属于一个特定的
core。不过它可以根据调度算法动态地迁移到另一个
core。作为运行在所有 core 上的调度器,这个服务可以在
seastar::sharded<>
的框架下实现。不过这个调度器和 Seastar
的原生调度算法还有一些区别:
-
seastar::sharded<>既可以在单个 core 上启动,也可以同时在所有 core 上一起 启动。 -
spdk_thread可以根据调度算法动态迁移。spdk_thread一般来说属于 一个 core 的,但是根据它的cpumask,一个spdk_thread可以 根据 CPU 的负载 迁移到cpumask包含的的任意一个 core。这一点 Seastar 尚无支持。 -
因为
spdk_thread自己有消息队列、poller 等基础设施,我们可以把它视为一个逻辑的 reactor。这个特性在 Seastar 目前还没有与之对应的实现。 -
每个 core 都维护着一组
spdk_thread。SPDK 甚至用 thread local storage 跟踪 其中一个。这个很像进程中的一组线程。spdk_get_thread()返回的就是被跟踪的 那个spdk_thread。目前 Seastar 的 reactor 并没有对应的概念,但是我们可以用 一个seastar::sharded<>服务来保存对应 core 上的所有spdk_thread。 -
允许动态地注册和注销 poller。SPDK 中有两种 poller。一种是系统级的,负责 保证 SPDK 事件系统和 reactor 的基本运作。另一种是用户级的,它允许实现具体功能 的模块自己定期轮询业务相关的事件。这些用户级的 poller 就是注册在前面提到的
spdk_get_thread()返回的线程中的。参见spdk_poller_register()和spdk_poller_unregister()的实现。如果继续沿着刚才的思路往前,我们可以把 一组spdk_thread保存在,比如说,seastar::sharded<spdk::ThreadGroup>里面, 让spdk::ThreadGroup来为它管理的spdk_thread服务。它会用reactor::poller::simple()来注册自己的do_complete()函数,后者遍历 所有的spdk_thread的 poller。也允许应用程序在任意时刻为指定的spdk_thread添加 poller。这个做法和 virtio 中vring<>的实现相同。 -
同时支持中断模式和轮询模式。这是 SPDK 最近加入的一个新特性,甚至允许应用的 poller 工作在可定制的中断模式。
节能、提高 CPU
的使用率和负载均衡,这些作为一个总体的设计目标,SPDK
做得相对比较深入。它根据线程的统计数据,比如说闲忙的时间比
(spdk_thread_stats),来决定如何调度,Seastar 仅在
reactor 的实现里面通过调用
pure_check_for_work() 来判断 CPU
当下是否有工作要做,如果没有的话,就进入浅层的睡眠模式。笔者认为,这也许不仅仅是工程量多少的问题。也可能是因为
Seastar
对自身的定位,它提供了基础的异步编程模型,异步调用,以及基本的
IO 调度,但是它并不希望干涉用户业务在不同 shard
上的分布,而是把这个问题留给应用的开发者。
要在 Seastar 的框架下实现
spdk_thread 的这些高级特性是完全有可能的:
-
根据负载动态调度工作协程:不仅仅
spdk_thread需要统计自己的关于调度的统计 信息,每个spdk::ThreadGroup也需要统计各自的idle_tsc和busy_tsc。 并提供接口供调度器查询,作为负载均衡的依据,然后在 shard 间调度任务。 -
和 SPDK 的 reactor 类似,
spdk::ThreadGroup也要保存一个 "leader" thread, 后者负责常规的 poller 注册和注销工作。 -
spdk::ThreadGroup启动的时候需要向 reactor 注册自己的总 poller,负责调用非 定时的 poller。 -
在新注册 poller 的时候,需要按照 poller 是否有周期区别处理。
-
如果 poller 指定了周期,那么需要新建
seastar::timer,并在spdk::ThreadGroup中维护一个 map,方便在运行的时候根据spdk_poller*找到seastar::timer暂停 或者注销。 -
如果是没有周期的 poller,那么直接加入当前
spdk::ThreadGroup的 leader thread。 让后者的 poller 来调用新注册的 poller。这种分层的设计也方便管理对象的生命周期和统计 运行时指标。
-
在 SPDK 里面,要发起一个异步调用最典型的方式,类似下面的代码:
rc = spdk_bdev_write(hello_context->bdev_desc,
hello_context->bdev_io_channel,
hello_context->buff,
0, length,
write_complete, hello_context);
这段代码摘自
examples/bdev/hello_world/hello_bdev.c。这里以
bdev 的 NVMe 后端为例:
-
从
hello_context→bdev_io_channel的 cache 或者 bdev 的内存池分配一个spdk_bdev_io -
用给定的参数设置这个
spdk_bdev_io,这样这个 I/O 就知道需要写的数据位置,长度,甚至 回调函数的函数指针和参数也保存在这个 I/O 里面了。 -
往
nvme_qpair的提交列表的末尾添加新的 I/O。 -
通过修改提交队列末尾的 door bell,告诉
nvme_qpair,提交列表里多了一个新的 I/O。
那么我们怎么知道 NVMe 设备完成了这个写操作呢?下面的函数处理指定的 queue pair 上所有完成了的 I/O 请求。
int32_t spdk_nvme_qpair_process_completions(struct spdk_nvme_qpair *qpair,
uint32_t max_completions);这个做法很像 io_getevents(),都是从完成列表收割完成了的 I/O 请求。这个过程很像播种和收割。提交请求就是播种,检查完成了的请求就像是收割。让作物成熟的魔法师就是轮询模式的驱动 (polling mode driver)。
既然 SPDK 用
spdk_thread
实现用户协程,那么协程之间要协作的话,该怎么做呢?就是前面提到的"发送消息"。消息保存在大小为
65535 的一个 ring buffer 里面。顺便提一下,其实 Seastar
也有类似的数据结构,称为
seastar::circular_buffer_fixed_capacity。如果有必要的话,我们甚至可以把 SPDK 的 event 和 thread
子系统完全换成 Seastar 的实现。
SPDK 的 then()
回调函数是 C
语言实现异步编程一个很简单直接的方式,但是它似乎和 Seastar 的
future<>
格格不入。SPDK 和 DPDK
一脉相承,有着深层的血缘关系,我们是不是可以照着
seastar::net::qp<> 实现 SPDK
支持呢?看上去这种基于成对的 submission 和 completion queue
的抽象也适用于很多 SPDK
的场景。先比较一下基于流的操作和基于块的操作有什么异同:
|
bdev |
|
|
|
发送 |
读写指令 |
发给对方的包 |
|
接收 |
设备状态 |
对方发来的包 |
|
等待 |
特定写指令的完成 |
发送的进度 |
|
等待 |
特定读指令返回的数据 |
下一个接收的报文 |
因为 bdev 需要跟踪特定请求的状态而不是一个
进度,所以我们无法使用
seastar::stream 定义 bdev
的读写接口。更好的榜样应该是 seastar::file。每个
posix_file_impl 都有一个
_io_queue 的引用,同一 devid 的所有
_io_queue 指向 reactor 统一维护的同一个
queue。这些 queue 用 devid 来索引。SPDK
作为专业的底层设施自然也有对应的设计。需要理解的是
io_sink、io_request 和
io_completion 这些组件是如何互相协作的。
还有个问题,SPDK
是一个有丰富接口的工具集,它有多个模块。每个模块都有自己的一组回调函数。光
bdev 就有 11 种回调函数:
typedef void (*spdk_bdev_remove_cb_t)(void *remove_ctx);
typedef void (*spdk_bdev_event_cb_t)(enum spdk_bdev_event_type type,
struct spdk_bdev *bdev,
void *event_ctx);
typedef void (*spdk_bdev_io_completion_cb)(struct spdk_bdev_io *bdev_io,
bool success,
void *cb_arg);
typedef void (*spdk_bdev_wait_for_examine_cb)(void *arg);
typedef void (*spdk_bdev_init_cb)(void *cb_arg, int rc);
typedef void (*spdk_bdev_fini_cb)(void *cb_arg);
typedef void (*spdk_bdev_get_device_stat_cb)(struct spdk_bdev *bdev,
struct spdk_bdev_io_stat *stat,
void *cb_arg, int rc);
typedef void (*spdk_bdev_io_timeout_cb)(void *cb_arg, struct spdk_bdev_io *bdev_io);
typedef void (*spdk_bdev_io_wait_cb)(void *cb_arg);
typedef void (*spdk_bdev_histogram_status_cb)(void *cb_arg, int status);
typedef void (*spdk_bdev_histogram_data_cb)(void *cb_arg, int status,
struct spdk_histogram_data *histogram);不过其中常用的可能只有:
typedef void (*spdk_bdev_io_completion_cb)(struct spdk_bdev_io *bdev_io,
bool success,
void *cb_arg);
typedef void (*spdk_bdev_get_device_stat_cb)(struct spdk_bdev *bdev,
struct spdk_bdev_io_stat *stat,
void *cb_arg, int rc);
前者用来处理一个完成了的
I/O,后者用来获取块设备的统计信息。回到刚才提到的
spdk_bdev_write()。对应的 Seastar 风格的一个
bdev 定义可能像这样:
class bdev {
explicit bdev(const char* name);
~bdev();
future<> write(uint64_t pos, const void* buffer, size_t len);
future<> read(uint64_t pos, void* buffer, size_t len);
future<io_state> stat();
};
这个接口和 seastar::file 对应,忽略了 io channel
这些 SPDK 独有的机制。问题是
-
是否需要使用 SPDK 的回调函数实现异步调用呢?
-
是的话,如何实现?
-
不是的话,又怎么处理?
对于第一个问题,笔者认为,如果没有必要,还是应当尽量使用 SPDK 的方法,而不是自己开发一套机制替代它,这样的好处显而易见:因为 SPDK 的公开方法相对稳定,这样能减少跟踪上游带来的维护成本,把对 SPDK 的改动减少到最小,同时也增加了这个改动进入 SPDK 和 Seastar 上游的机会。但是新的问题出现了:
-
这个回调函数是什么?
-
我们可以把回调函数定义成为一个
bdev的静态成员函数,便于访问它的私有成员。 -
回调函数应该能调用
_pr.set_value(res)。其中,_pr是和返回的future<>对应的promise<>。
-
-
回调函数的参数呢?这个参数至少要让我们能定位到
_pr。在 AIO 后端的实现里面, 当它在 poller 里面收集到完成了的事件之后,依次调用事件对应的completion→complete_with()函数。下面是从 Seastar 摘录的相关代码:
r = io_pgetevents(_polling_io.io_context, 1, batch_size, batch, tsp, active_sigmask);
for (unsigned i = 0; i != unsigned(r); ++i) {
auto& event = batch[i];
auto* desc = reinterpret_cast<kernel_completion*>(uintptr_t(event.data));
desc->complete_with(event.res);
}
而 io_completion 则会调用
io_completion::complete(res)。后者由
io_completion 的子类各自实现。以
io_desc_read_write 为例,它从
io_completion 继承,并负责与 fair_queue
沟通,也保存了 _pr。在
io_desc_read_write::complete() 里,
_pr.set_value(res);
delete this;
如果不使用回调函数的话,我们其实也需要模仿现有 Seastar 中对
aio
的支持,自己实现一个基于队列的轮询机制。我们以写文件为例,看看
Seastar 的 AIO 后端的实现吧。在
posix_file_impl::do_write_dma() 中,它调用
engine().submit_to_write():
-
io_queue::queue_request()-
构造一个
unique_ptr<queued_io_request>对象 -
把
queued_io_request::_fq_entry加入io_queue::fair_queue队列。通过这个_fq_entry是可以找到包含它的queued_io_request对象,并顺藤摸瓜,找到kernel_completion -
返回
queued_req→get_future()
-
然后开始了接力比赛,接力棒就是 I/O 请求:
-
第一棒:把 I/O 请求从 io queue 取出,经由按照它们所属类型的权重分配的公平队列, 加入
io_sink::pending_io。
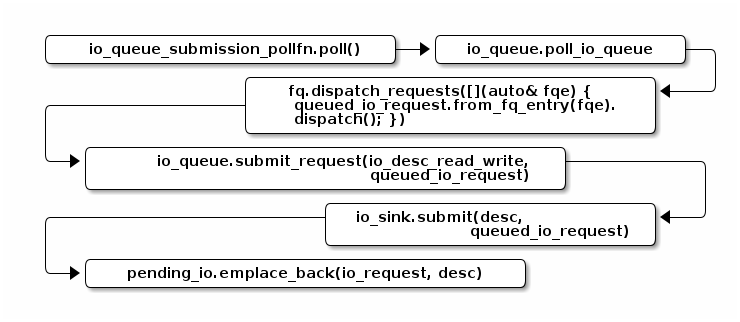
-
第二棒:从
io_sink::pending_io取出 I/O 请求,把这些请求加入 AIO 的io_context队列,换句话说,就是把请求加入 submission queue。
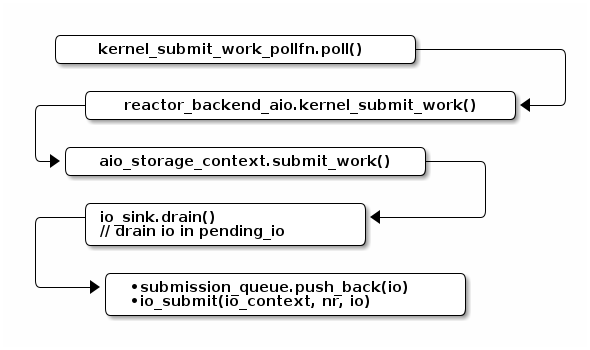
-
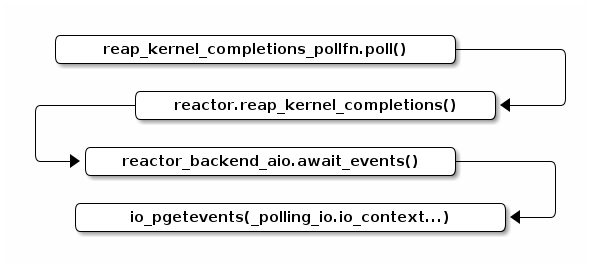
第三棒: 使用
io_pgetevents()系统调用,读取 completion queue 里面的异步 I/O 事件。
事实上,Seastar 的 I/O 子系统用了 5 个 poller
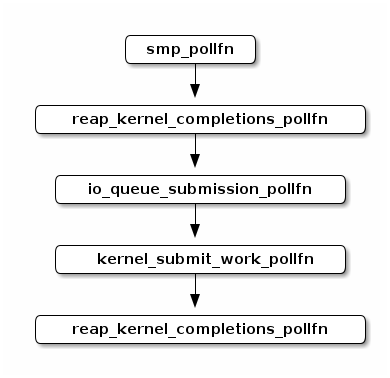
请注意,这五个 poller 的执行顺序影响着请求的延迟。因为后面一个
poller 的输入可能就是前一个 poller
的输出。这样同时也有助于减小内存子系统的压力,因为请求在 queue
里面积压的数量和时间越长,就意味着有越多的内存不可用。而这些内存有相当部分是按照下面存储介质的块对齐的,可能会有更多的内部碎片。所以尽早地释放它们,也更有利于提高系统的性能。这里有两个
reap_kernel_completions_pollfn 是希望一个 poller
能及早地释放 I/O queue 里面的 I/O 占用的内存空间;而让另一个
poller 能处理那些立即返回的 I/O 请求。
如果 Seastar 使用 SPDK 作为其存储栈,可能也需要对应的 poller:
-
smp_pollfn: 处理其他 reactor 发来的 I/O。它们可能也会访问当前 core 负责的 bdev。 -
reap_spdk_completions_pollfn: 尽早地处理完成了的 I/O 请求, 减轻内存子系统的压力,也减小延迟。 -
io_queue_submission_pollfn: 按照不同优先级把 I/O 入列 -
spdk_submit_work_pollfn: 把 I/O 从队列里面取出,提交给 SPDK -
reap_spdk_completions_pollfn: 调用spdk_thread_poll()收集完成了的请求。
当然也可以从简处理
-
不用
smp_pollfn。即不支持跨 shard 发送 IO 请求,每个 shard 都用自己的 io channel。 -
不用第一个
reap_spdk_completions_pollfn。因为我们觉得这是个优化,以后慢慢加。 -
不用
io_queue_submission_pollfn,因为 SPDK bdev 层有自己基于 token bucket 的 QoS。 -
不用
spdk_submit_work_pollfn,既然不用 Seastar 的 fair queue,那么也不用从 io_queue 里捞 I/O 请求了。 -
只保留
reap_spdk_completions_pollfn。把一切都交给 SPDK。
现在我们应该能回答刚才的问题了:
回调函数的参数呢?
只要能把 I/O 请求包装成某种类似
io_completion 的类型,让它
-
能跟踪当初调用异步操作时,返回的
promise<>以及 -
能包含在回调函数的参数
cb_arg中,以便在 I/O 完成的时候, 通知对应的_pr,并且更新必要的统计信息。
就可以了。这里有两个思路:
-
让
spdk_bdev_io包含 SPDK 版的io_completion。在回调函数里 通过spdk_bdev_io引用对应的io_completion。但是spdk_bdev_io更多的是作为 SPDK 开放给模块的实现者的接口,而非给应用开发者的接口。 注意到bdev.h中,不管是读还是写操作,I/O 的接口基本只有两类-
void *buf、uint64_t offset和uint64_t nbytes -
iovec iov[]、uint64_t offset和uint64_t nbytes
-
上层应用在发送请求的时候是没有机会接触到
spdk_bdev_io 的,更遑论在它后面的
driver_ctx 中夹带"私货"了。况且
driver_ctx 的本意是让 bdev 的下层驱动加入自己
context,并不是提供给上层应用的。这条路走不通。
-
在发送 I/O 请求的时候单独构造 SPDK 版的
io_completion,把它 作为cb_arg交给 SPDK。在回调函数里还原io_completion, 再如前所述,做相应的处理。
SPDK 在 Seastar 中的形态
这里希望讨论 SPDK 在 Seastar 框架中的角色,以及呈现的接口是什么样子的。
另外一个 reactor?
前面关于 poller 的讨论引出了一个问题,即
我们能重用 Seastar 的这几个 poller 吗?
这个问题在一定程度上等价于:
我们需要实现一个基于 SPDK 的 Seastar reactor 吗?
在阅读 Seastar reactor 实现的时候,可能会注意到,
reactor_backend_selector 就是用来根据
--reactor-backend 命令行选项来选择使用的
reactor
后端的。这种类似插件的框架允许我们可以实现一个新的后端。虽然我们能够在
SPDK 的框架下
-
加入 poller,并使用非阻塞的调用
-
使用 aio 读写普通的文件
-
使用
sock模块
把上面这些功能组合起来,足以实现一个功能完备的
reactor_backend。但是也可以保留 Seastar 的
reactor,像 DPDK 那样另外再注册
spdk::ThreadGroup 的
poller。牵涉面小,而且工作量也少些。对于两者的集成这可能是更稳妥的第一步。也许这也是
SPDK 支持在 Seastar
中更合适的定位—即提供块设备的访问,而非作为通用的基础设施提供文件系统的访问。这两者有共性,但是也有一些不一样的地方。比如说文件系统可以用
open_directory() 和
list_directory()
来枚举一个目录下的所有文件,更进一步,块设备的枚举方式根据块设备的类型各自不同。SPDK
提供 spdk_nvme_probe() 来列举所有的 NVMe
设备,用 spdk_bdev_first() 和
spdk_bdev_next()
来找出所有的块设备。另外,为了提高并发,SPDK 引入了 io
channel 的概念,它也很难直接映射到 Seastar 基于文件系统的 IO
体系里面。所以比较好的办法还是先把 SPDK 在 Seastar
下实现成相对独立的模块,而不是试图把它实现成为一种和 AIO 和
epoll 并列的通用异步后端。另外,在初期最大程度保留 SPDK
的基础设施,最小侵入的实现可能是比较稳妥的途径。
典型的用例
我们用假想中的 Seastar + SPDK 重写
examples/bdev/hello_world 试试看
namespace bpo = boost::program_options;
seastar::logger spdk_logger("spdk_demo");
int main(int ac, char** av) {
seastar::app_template seastar_app;
seastar_app.add_positional_options({
{ "bdev", bpo::value<std::string>(), "bdev", 1 },
});
spdk::app spdk_app;
return seastar_app.run(ac, av, [&] {
auto bdev_name = seastar_app.configuration()["bdev"].as<std::string>();
return spdk_app.run(seastar_app.configuration(), [bdev_name] {
auto dev = spdk::block_device::open(bdev_name);
uint32_t block_size = dev.block_size();
size_t buf_align = dev.memory_dma_alignment();
auto buf = spdk::dma_zmalloc(block_size, buf_align);
return dev.write(0, buf.get(), buf.size()).then([&] {
memset(buf.get_write(), 0xff, buf.size());
return dev.read(0, buf.get_write(), buf.size());
}).then([&buf] {
temporary_buffer<char> good{buf.size()};
memset(good.get_write(), 0, good.size());
if (int where = memcmp(good.get(), buf.get(), buf.size());
where != 0) {
spdk_logger.error("buf mismatches at {}!", where);
} else {
spdk_logger.info("buf matches!");
}
}).finally([buf = std::move(buf)] { });
}).handle_exception_type([&] (std::system_error& e) {
spdk_logger.error("error while writing/reading {}", e.what());
});
});
}
其中,spdk::app::run() 会初始化 SPDK app
的运行时。比如说
-
调用
rte_eal_init() -
启动 SPDK 的工作协程调度器
-
启动 RPC 服务
-
加载各个子系统
它还会负责 SPDK 的清理工作。
spdk::bdev 将会是一个
seastar::sharded<> 服务。spdk::do_with_bdev()
则是 spdk 提供的一个 helper,它负责初始化
bdev 实例,在合适的时机调用
bdev::start() 和
bdev::stop(),把根据第一个参数初始化完成好的
bdev 实例传给自己的另外一个参数,由后者使用
bdev。虽然这里以 bdev 模块为例,将来 Seastar 和
SPDK 的集成并不会局限于 bdev 模块。