如何用在 Seastar 里用上 IORING_OP_SEND_ZC?
引子
linux 6.0 为我们带来了 zero-copy 网络传输的 io_uring 支持。但是 Seastar 对 iouring 的支持仍然很有限,它仅仅支持下面几种操作
-
read
-
write
-
readv
-
writev
而迄今为止 io uring 已经支持了 48 种异步操作,这四种操作只是冰山一角。本文希望讨论一下如何为 Seastar 加入一部分网络 IO 的 io_uring 支持。
Seastar 的磁盘 IO
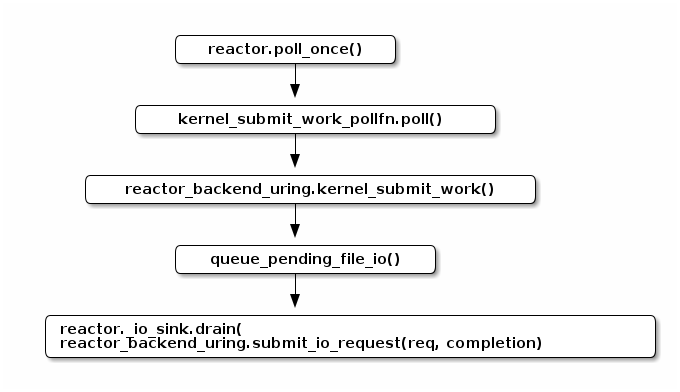
让我们先理解
reactor_backend_uring 是如何工作的。下面是
reactor_backend_uring
提交 IO 请求的调用路径。可以注意到,Seastar
是成批地提交请求的。而且请求并不是在
poll_once() 的时候创建的,它们往往在类似
posix_file_impl::do_write_dma()
的地方创建,并加入当前访问文件所对应的
_io_queue 队列。
那么 _io_queue 是什么呢?Seastar 为了解决多 shard
共享磁盘 IO,同时最大化其吞吐量的问题,设计了
用户态的 IO 调度机制。避免在 shard
之间搞平均主义和大锅饭,导致低效和拥塞。为了在核之间统筹规划
IO,Seastar 为每个设备定义一个
io_group,同时让每个 shard
都持有和需要访问的设备对应的
shared_ptr<io_group>。为了安放还不能服务的
IO 请求,每个设备在每个shard 上的
engine 都有自己的
io_queue。因此可以看到所以如果程序部署在 32
核的机器上,同时有 16 块硬盘,那么每个核都会有 16 个
io_queue,分别对应自己负责访问的硬盘。
另外,也需要注意
reactor_backend_uring::submit_io_request()
的实现,
auto sqe = get_sqe();
switch (req.opcode()) {
case o::read:
::io_uring_prep_read(sqe, req.fd(), req.address(), req.size(), req.pos());
break;
// ...
}
::io_uring_sqe_set_data(sqe, completion);
_has_pending_submissions = true;get_sqe() 是一个循环:
io_uring_sqe* sqe = nullptr;
for (;;) {
sqe = io_uring_get_sqe(&_uring);
if (sqe) {
return sqe;
}
io_uring_submit(&_uring);
for (auto cqe : io_uring_peek_batch_cqe()) {
cqe->complete();
io_uring_cqe_seen(&_uring, cqe);
}
}这里有两个需要注意的地方:
-
IO 请求都是从
io_queue里面取出来的。而io_queue是用户态 IO 调度器的一部分。显然,这个 IO 调度器并不包含网络 IO。 -
和 aio 不同,io uring 后端的
kernel_submit_work()除了执行 submit 的动作,在 sqe 不够的时候也会执行reap_kernel_completions()。
不过笔者认为,如果 sqe 不够用,那么收割 cqe 有可能是无济于事的。除非内核的网络子系统会因为用户取走 cqe 不够快而减缓 sqe 的处理。
既然只有存储子系统的请求会走到这里,那么 Seastar 怎么处理网络上的 IO 请求呢?
Seastar 的网络 IO
下面是 Seastar 写入 output_stream 流的调用路径:
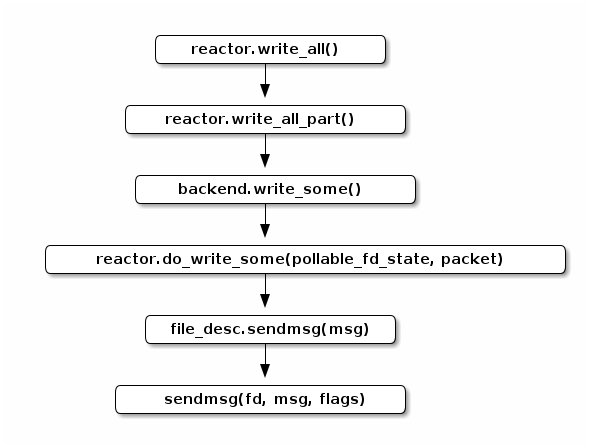
其中,reactor::do_write_some() 的实现类似
co_await writeable(fd);
msghdr mh = {
.msg_iov = p.fragment_array(),
.msg_iovlen = p.nr_frags(),
};
fd.sendmsg(&mh);
所以 reactor::do_write_some() 会等到 fd
可以写入的时候,再进行系统调用,确保这个
::sendmsg() 是不阻塞的。
可以看出这两类 IO 在 Seastar 里的处理方式很不一样。
如何让 Seastar 的网络 IO 用上 io_uring
网卡和硬盘
再看硬件设备的异同点:
-
一方面,网卡有和存储类似的属性,比如说,它们都有吞吐量、队列深度这些全局的硬件指标。
-
另一方面,一般来说网卡和存储相比有高得多的吞吐。毕竟 40Gbps 的万兆网卡几百块就可以买到。 3100MB/s 的企业级固态盘的价格仍然高居不下,从数千到上万不等。这样也解释了为什么 Seastar 开发者为什么对用户态 IO 调度这么重视。
-
最后,一般服务器可能只会安装两块网卡。但是可能会有一个 36 x 3.5寸盘位的高密机箱。
那么把磁盘 IO 的用户态调度器的机制套用在网络 IO 上是否可行呢?答案是否定的。一台服务器上可以有多个网络出口。网卡也可以支持虚拟化,比如 SR-IOV,或者用 bond 把多块物理网卡捆绑成一块逻辑网卡。为了后面讨论简单起见,我们把这些网络出口简称为网卡。操作系统通过路由表来决定特定网络包使用哪块网卡。而我们在读写网络 socket 的时候,分两种情况
-
读:这里我们无法预判将要读到的网络包是经由那块网卡发来的。本机路由表仅仅定义我们转发包的规则, 但是它没有定义交换机把数据包发给本机的哪块网卡。
-
写:路由规则是系统层面的设置。就算我们在用户态可以根据路由表来判断发出的网络包会选用那块网卡, 并且根据这个信息和网卡的带宽来做 shard 间的公平调度,这也是很麻烦的事情。
因为网卡的总体吞吐能力大大超过了存储设备,同时访问特定网段的网卡只有一两块,而我们的存储子系统常常需要同时和几十块硬盘打交道。所以为网络 IO 定义用户态调度器一方面难度挺高,一方面效益也不大,并且有的场景无法覆盖。如果只有单块网卡的话,问题稍简单一些。但仍然会是个投入产出不成正比的工程。
乐观和悲观
前面得出了不需要用户态 IO 调度的结论。那么发送网络 IO 还需要
io_queue 吗?如果
io_queue 不用来实现 per-shard
的公平队列,那么它的意义只是在于临时保存 IO
请求,让我们可以在成批地构造和发送 IO 到 sq
里面去。新的问题来了,什么时候 发送 IO
呢?或者说,我们应该/可以立即发送 IO 吗?有两个选择:
-
在
reactor_backend_uring::write_some()里 -
在
reactor_backend_uring::kernel_submit_work()里
如果我们退后一步看,其实也可以乐观地用
sendmsg(…, MSG_DONTWAIT)
先试试看,如果系统返回 EWOULDBLOCK,那么再用
reactor::do_write_some() 的方式来处理这个
IO。我们知道,在内核里面的读写都是有 buffer
的。所以如果写缓冲区大小为 4k,每次只写 512
字节,那么我们可以连着写 8 次都不需要检查
POLLOUT 。当然,在第 9 次的时候, 就会返回
EWOULDBLOCK
了。这时我们可以切换到悲观模式,一旦写请求返回了,说明内核至少消耗了一部分缓冲区,这时我们可以重新振作,回到乐观模式。乐观模式可以直接在
reactor_backend_uring::write_some()
直接把请求发送给内核,而悲观模式的工作则需要在
reactor_backend_uring::kernel_submit_work()
完成处理。
只要非阻塞的操作有“惯性”,那么我们就可以使用“乐观模式”和“悲观模式”的设计。因此,它也适用于其他
reactor backend。不过对于 io_uring 需要特别的权衡。因为
sendmsg(…, MSG_DONTWAIT)
本身仍然是一次系统调用,如果我们希望使用 SQPOLL
模式的话,这个开销是不容忽视的。如果不采用 SQPOLL
模式,那么把一次
sendmsg(…, MSG_DONTWAIT) 和两次
io_uring_submit()
以及相应的两次协程切换相比,哪个效率更高,延迟更低呢?笔者认为“不好说”。但是对于高性能网卡来说,很可能前者性能更好。因为它能更早地把请求交给内核。而非
SQPOLL 模式下,两次
io_uring_submit()
可是两次结结实实的系统调用。虽然这两次系统调用的开销可能可以分摊到发送的多个
sqe 上,但是对单个 IO 产生的延迟却是实实在在的。
如果不用“乐观模式”,假设我们只在
reactor_backend_uring::kernel_submit_work() 和
reactor_backend_uring::wait_and_process_events()
里面调用
io_uring_submit(),那么这两个选项的延迟是相同的。毕竟,内核只能看到 submit
之后的 sqe。
io_queue
从设计方面考虑,每个 reactor 都有自己的
io_sink,"sink" 可以理解为汇聚地。在
c91d9e6
里面,作者提到
io_uring has a lot more operation types, and we would like to keep them all in the same descriptor, so they can be used by the same queue.
这里的 “descriptor” 指 io_request。所以 Glauber
当初希望把更多的(或者说所有的) io_uring 操作统一成
io_request
放在一个队列里面。这样的好处应该是设计更一致,如果从性能角度分析的话,大概是
CPU 的 icache locality 更好吧。而且
_io_sink 并非只为
io_queue 服务。reactor::fdatasync()
就是个例子。它直接构造 new 出来
io_completion 和
io_request,把它们扔进了
_io_sink。大家可能会担心因为在 IO
路径上频繁动态内存分配,是不是会造成的性能问题。那么这真的是个问题,那么这个问题早已有之。因为
Seastar 里面的 io_request 其实就是
new 出来的,可以看看
posix_file_impl::do_read_dma() 的实现。在把
io_request 加入
io_queue 的时候,会新建一个
queued_io_request。它就是动态分配的,里面的
io_desc_read_write 继承自
io_completion。前者告诉 reactor
读写操作完成的时候应该做什么。后者是一个虚基类。自然
io_desc_read_write 也是动态分配的了。所以以存储
IO 的标准来评判,为每一个网络IO 动态分配
io_comlpetion 和
io_request 并不是很过分的事情。不过我们在实现
io_uring 支持的时候,可能无法重用
io_desc_read_write 了。因为它是用户态 IO
调度机制的一部分,其中还包含着公平队列的实现。
前面的讨论基本确定了我们倾向于用
io_completion 、 io_request 和
io_sink 的组合来发送 uring
请求。但是读者是否还记得
reactor::do_write_some() 的实现呢?它先等待
writable(fd)。这事实上起到 throttle
的作用,如果内核来不及消化这许多 IO 的话,fd 是不会 writable
的。那么 io_uring 的各种操作呢?如果我们希望用 Seastar
编写一个异步的 API
网关,那么在客户端发送大量请求的时候,倘若没有内核的反馈,可能会产生海量的
io_request 堆积在
io_sink
里面。这对性能不仅没有帮助,反而会短时间内消耗大量内存用于保存
io_request 以及
payload。笔者认为,可能更好的方式应该是在
reactor_backend_uring::write_some() 中加入类似
co_await writable(fd) 的环节。但是 Avi
还是建议直接把请求扔给 io_uring,这样可以获得更低的延迟。
因为使用 io_uring 提交 sendmsg
请求的几个步骤基本是不阻塞的:
auto sqe = io_uring_get_sqe(&ring);
io_uring_prep_sendmsg_zc(sqe, fd, &msghdr, msg_flags);
io_uring_sqe_set_data(sqe, i);
io_uring_submit(ring);
如果使用 IORING_SETUP_SQPOLL,io_uring_submit()
甚至不用陷入内核态,从而有更低的延迟。毕竟应用程序自己是可以设计
back pressure 机制的。如果希望在提交请求之前等待 poll
的结果,用这种方式实现 back pressure
则会提高延迟。这个想法的出发点并没有问题,但是它加重了
io_uring 的负担。因为每个
poll(2)
调用和返回值的处理,对应用程序和内核都会是个额外的开销。
所以沿用之前的基于预测(speculation)的设计,用 Python 伪代码来写就是:
async def write_some(self, fd, msg):
if fd.speculation.non_block_tx.test_and_clear():
r = fd.sendmsg(msg, MSG_DONTWAIT)
if r > 0:
if r == msg.len:
fd.speculation.non_block_tx = True
return r
elif r != -EAGAIN:
raise Exception(r)
return await self.submit_request(prep_sendmsg(msg, 0))
在这里采用了同步非阻塞和异步阻塞调用相结合的设计。如果上次的写操作完成了,没有
short write,则大概率这次能够进行非阻塞的写,所以直接使用
POSIX 非阻塞的系统调用,如果运气不好的话,就把请求发给
io_uring 采用阻塞的调用。需要注意,如果我们用
O_NONBLOCK 打开这个文件的话,那么
prep_sendmsg() 的 sqe 可能会返回
-EAGAIN 或者 -EWOULDBLOCK,而
io_completion::complete_with()
看到这个错误会把它当成
std::system_error(EAGAIN, std::system_category())
扔出来。这个行为和其他的 reactor
后端会不兼容。所以要么我们让 io_completion
能为我们网开一面,让我们有重试的机会。或者干脆用阻塞的
IO,即在打开文件的时候不指定
O_NONBLOCK。后者要容易一些。对于普通文件的写操作,因为 write 不提供
MSG_DONTWAIT 的
flag,我们无法使用刚才的策略。为了不阻塞 reactor
所以只能使用 O_NONBLOCK 打开文件,POSIX 的
write 返回 -EAGAIN 的时候,等待 writable
之后,再提交新的写操作:
async def write_some(self, fd, buffer):
if fd.speculation.non_block_tx.test_and_clear():
r = fd.write(buffer)
if r > 0:
if r == msg.len:
fd.speculation.non_block = True
return r
elif r != -EAGAIN:
raise Exception(r)
await self.submit_request(prep_poll(fd, POLLOUT))
return await self.submit_request(prep_write(fd, buffer))笔者想,io_uring 的一个优势是减少系统调用,提高总体的性能。但是这种基于预测的 IO 的执行方式在理想情况下并不能减少系统调用,虽然它能在及时消耗 buffer 的情况下减少延迟。正如 Avi 提到的
we can have latency of 0.5ms even though data is ready because the reactor will prefer to run tasks and gather more I/O.
所以只要能 inline 地发送 IO,我们就会直接把请求直接发送出去,而不是等 reactor 的工作线程把“一天”工作都完成,在下班的时候“顺路”把当天收集到的 IO 成批地发送出去,那样的延迟会比较高。SQPOLL 的引入是不是会改变这个状况呢?因为在 SQPOLL 模式下,内核的 SQPOLL 线程会帮我们发送 sqe。这样的话,直接 inline 地发送请求就可以了,而不用把 IO 请求加入队列,统一处理。
文中的提议已经写成了
PR#1235,一旦这个 PR merge,那么
IORING_OP_SEND_ZC 也就不远了。