说说 awaiter 的生命周期,和最近一位同事发现的
maybe_yield_awaiter 的 bug。
一个协程如果流程很长,而且它运气也很好,没有被打断的话,那么就会长时间地占用
CPU,导致这个核上的其他任务被饿死
(starve)。我们知道,协程之所有叫做“协”程,就是因为协程和协程大家都是谦谦君子,互相礼让协作,这样才能有比较好的响应和延迟。Seastar
中的协程用 maybe_yield_awaiter() 中途把 CPU
出让给 (yield)
别人,这个函数会检查当前是不是有正在亟待处理的事件。如果有的话,它就会抢占当前的协程,把它手里的
CPU 借用一会儿,把急事完成了,再把 CPU 还回来。
比如说,如果协程有个很大的循环,处理上万个元素,那么我们很可能会在循环里面插上几个
co_await coroutine::maybe_yield();让这个协程也能照顾一下其他人的需要,避免导致 reactor 出现 stall 告警。
co_await
在讨论 bug 之前,还是需要和大家一起再复习一下
co_await 。毕竟协程是比较高层的抽象,而
C++20
的协程又很灵活,需要编译器和协程库,乃至用户程序的通力协作才能完成工作。
C++ 中的
co_await
是个操作符,后面跟着操作数,即一个表达式:
co_await expr
中的 expr 需要根据具体情况通过不同方式转换成
awaitable,这样 co_await 才能知道下一步是
走还是留 继续还是歇会儿再来。在这里,
maybe_yield() 构造一个
maybe_yield 的 awaitable 对象,它的
co_await
操作符的实现的返回值是个 prvalue。所以按照
cppreference
的说法,最终的 awaiter 是这个 prvalue
materialized
之后的临时对象。
不管怎么样,我们找到了 awaitable 的最终所在:故事的主角
maybe_yield_awaiter
。这个临时对象和调用者协程定义的其他局部变量一样,存活在栈上。具体说,是存活在
coroutine frame 上,在
maybe_yield_awaiter::await_ready() 告诉 coroutine
runtime 它要暂停运行之后,
maybe_yield_awaiter::await_suspend()
把自己直接挂到任务队列上去,要求被调度恢复执行。
maybe_yield_awaiter
等待的结果一旦出现,它就得以恢复运行,虽然这里的结果是
void,
maybe_yield_awaiter::await_resume()
仍然会被调用,它负责为
co_await 的调用方提供返回值,毕竟
co_await expr 是允许返回值的。
task 和 waiting_task()
前面提到, maybe_yield_awaiter 可以用来出让
CPU。但是需要重点提出的是,
maybe_yield_awaiter 是继承自
task 的。那么什么是 task 呢?
在 Seastar 中,task
代表着一个可调度的最小的任务单位,如果大家看看
future::schedule() 就会注意到,它其实直接
new 了一个 task。如果这个 task
不能立即返回的话,它会被当成参数传给
::seastar::schedule() 。而
seastar::schedule() 的作用就是把
task 加到任务队列上去。在调度器调度执行
task 的时候,它会调用
task→run_and_dispose() 。请注意,这里的
task 就是
maybe_yield_awaiter
这个对象的地址。所以可以看出来,我们有个前提,即在这个 task
调度完成之前,这个指针都是有效的。因为
maybe_yield_awaiter 应该保存在调用者的 coroutine
frame 上,所以 *this 在
maybe_yield_awaiter::await_resume()
返回前都一直是有效的。自然这个前提是成立的。这里把和
task 相关的函数摘录下来:
struct maybe_yield_awaiter final : task {
template <typename T>
coroutine_handle_t when_ready;
task* main_coroutine_task;
template <typename T>
void await_suspend(std::coroutine_handle<T> h) {
when_ready = h;
main_coroutine_task = &h.promise(); // for waiting_task()
schedule(this);
}
virtual void run_and_dispose() noexcept override {
when_ready.resume();
// No need to delete, this is allocated on the coroutine frame
}
virtual task* waiting_task() noexcept override {
return main_coroutine_task;
}
};
那么问题来了,
waiting_task() 是做什么用的呢?每个
task 都会实现它,这里,
maybe_yield_awaiter
返回的是它调用者的地址,而且,有意思的是,虽然
maybe_yield_awaiter::await_suspend()
是个模板函数,它却对 T 有着很强的假设。它要求
std::coroutine_handle<T>::promise()
的类型是个 task !换句话说,它认为它的调用者的
promise 肯定是个 task 。我们去看看
coroutine_traits_base::promise_type
,它还真的是个 task 。如果每个
task 都知道自己调用者的
task,那么如果说协程从最外面的调用者一层一层地调用到最里面,构成了调用的链条。那么我们用
waiting_task()
其实也可以从最里面一层一层地,遍历这个链条的所有环节。如果大家用过
gdb 的话,就能意识到,这其实可以实现
backtrace 类似的功能,backtrace 通过
$bp 能找到之前的栈顶。而 Seastar 通过
waiting_task()
调用栈里面更高一层,道理是类似的。用图表示:
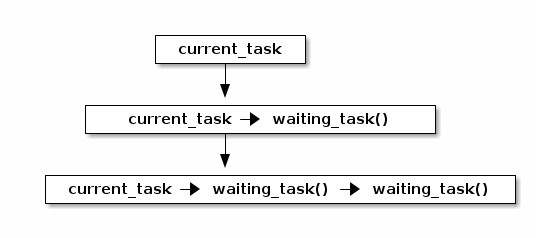
Seastar 中的 current_tasktrace() 用 Python
伪代码可以这么写:
def current_tasktrace():
stack_traces = []
task = local_engine->current_task()
while task is not None:
stack_traces.append(task_entry(task))
task = task.waiting_task()
return stack_tracesfolly 甚至专门有好几期 blog 介绍它家的 stack trace 是怎么实现的。协程 backtrace 对于程序员的重要性可见一斑。要在生产环境里面使用的话, backtrace 的支持是必不可少的。
问题分析
在普通的程序调用中,有压栈就要有退栈。协程也是一样的,子协程需要把自己的
waiting_task 设置成父协程的 task
指针。而在调用子协程的时候,
schedule(this) 会把自己作为 task
挂到执行队列上去,当调度器执行 task 的时候,把
_current_task 设置成指向这个
task 指针。结合该 task 的
waiting_task()
方法,就能一层一层地回到最外层的调用者。当子协程退出的时候,它就需要把
_current_task 改回来,设置成调用者的 task ,即
main_coroutine_task 。因为
maybe_yield_awaiter 和 C++20 coroutine
之前的 Seastar
的协程不一样,它不是通过把一系列表达式串联起来形成的程序执行流程,而是借助
C++ 编译器、标准库和用户实现的 awaiter 完成的。基于
future-promise 的协程 中,在前序 future 完成之后,后面的
future 在调度时,会执行
schedule() 的动作,这样可以确保
_current_task 一直指向的是最新的
task。但是后者如果通过 awaiter
来实现子协程的话,而且子协程又是以
task
的形式被调用的话,那么在子协程准备回到父协程的时候,就需要把当时调用自己时
schedule(this) 产生的副作用消除掉,即如前所述
engine()._current_task = main_coroutine_task;这样,如果父协程出错的话,那么它的 backtrace 才是准确的,否则第一个 frame 就会指向一个已经被释放的地址,即 use-after-free 。
那么我们是不是真的需要在 backtrace 里面包含
maybe_yield_awaiter 呢?这里引用一下 folly blog
的话
Probably the most frequent place where developers see stack traces is when programs crash. The folly library already provides a signal handler that prints the stack trace of the thread that is causing the program to crash.
所以大家平时都是发现有个地方出问题了,才会看看那个地方到底在哪里。而
maybe_yield()
是一个不会出问题的地方,它做的事情就是什么都不做。自然也不会出错,或者崩溃。举例来说,在一个多线程的程序崩溃的时候,使用
GDB 的
thread apply all backtrace
命令我们可以看到程序每个线程的
backtrace。对协程的程序来说,利用刚才提到的
_current_task 和
waiting_task() ,我们也可以手搓出来个协程版的
coroutine apply all backtrace。而这些 backtrace
里面是不会包含那个做好事 yield
的协程的,因为人家做好事不留名,把运行的机会让给了别人。留名的那位是正在运行的协程。因此,在
maybe_yield_awaiter 里面实现
waiting_task() 并没有意义,更进一步,把它实现成
task 也不再有意义了。因为它的作用就是
-
是否需要 yield
-
yield 的话,在挂起之前,把父协程的挂在执行队列上。说明它已经准备好了, 随时可以运行。
-
直接实现了前面两点
-
把
task的继承关系去掉了。