QoS,而且是分布式的。
QoS
如果一个服务有多个服务对象,那么就得分轻重缓急。但是也不能因为有些服务对象不重要,就完全不顾它们。举个例子,就算平时工作再忙,上个月的报销单也应该及时填啊。那么怎么实现 QoS 呢?还是用报销单的例子,那么我们定个规矩吧:每天至少用半小时时间填报销,要是做不完的话,那么就明天继续做。在执行之前,我们需要先引入几个概念:
-
任务:也就是要做的事情。每件事情都有它的优先级,还有它要花费的时间。
-
任务列表:要是任何时候,手里面只有一件事情,我们可能就不用操心 QoS 了。但是现实是,很多时候别说不同优先级的,就是同一优先级的任务都可能同时有好几件。我们一般按照先到先服务的原则,把它们放到队列里面,挨个处理。
-
分类:把要做的事情按照优先级分成几种。
-
计量:每个任务需要的时间都不一样,如果只是处理会议的邀请,那么可能只需要几秒钟就能做出回应。但是如果是分析一个新的编译错误,可能就得花半个小时。
-
调度:接下来该从哪个队列里做哪个任务呢?
我们还需要继续细化刚才的规定,这半个小时时间是排在什么时候呢?要不下午一点开始吧。对应到刚才的概念就是
-
任务:每天的工作,比如处理信件,填报表单,当然还有调试程序。
-
任务列表:每件工作按照先后顺序记到小本本上。做完一件就划掉一件。有新的工作就记在最后面。
-
分类:工作分成两类:一类是平时的工作,另一类是低优先级的维护工作,比如说报销。
-
计量:对列表里的工作根据工作量一一进行评估。
-
调度:现在到一点了吗?还没到,那么看看“正事儿“列表里面下一项是什么?到了的话,看看另外一个列表有没有东西,没有的话,就先做正事儿。反过来也是这样,就是如果今天正好没有其他事情的话,即使没有到一点钟,那么也不妨把积攒的报销单填了。
所以对我们来说,每当要开始下一个任务的时候,要回答的问题就是,我应该看哪个任务列表呢?刚才的设计定义的算法是一种比基础的优先级队列 (priority queue)调度更复杂的算法。它不仅仅为不同性质的任务定义了具有两个优先级的队列,而且为了防止低优先级任务得不到执行,还为它们保留了最小的带宽。
Clock
在说 mClock 之前,我们先说说几个指标:
-
weight (share) :这个类型的任务能使用多少比例的资源。如果一个系统里面需要进行数据迁移,那么它可以占用的带宽比例就可以很高。
-
reservation:这个类型的任务最少能保证得到多少资源。如果系统里面需要有低延迟的应用,比如说远程桌面或者交互式的网络游戏,那么就必须保证最低的带宽。但是这种应用需要的 weight 可能就相对低一些。
-
limit: 使用资源的上限。比如说刚才说的数据迁移的应用,它可能就需要设定一个上限,在资源吃紧的情况下,防止它挤占其它应用的带宽。
刚才的算法里面只支持前两个指标。mClock 的目标是同时支持这三个参数。论文前面列举了一些算法,这些算法解决的问题分为三类:
-
按照应用指定的权重分配带宽
-
除了按照比例分配带宽之外,还能照顾对于延迟比较敏感的应用
-
除了按照比例分配带宽,照顾延迟,还能预留最低的带宽
但是 mClock 不仅仅能支持这些功能之外,还支持指定上限,并且能根据资源的容量动态地进行调整。比如说,一个系统它接入的是一个网络存储,因为分布式的存储系统和本地存储相比有着更多的变数和不确定性,那么这个系统能获得的存储的带宽可能就是动态的。根据网络系统的设置,以及存储系统提供给它的带宽而定。
mClock 先从 tag-based 调度算法开始。 标签是指每当调度器看到一个新的请求,就会给它贴一个标签。标签上有几个之后要用到的数字。这个很像是去饭馆吃饭时,拿到的预约单号。当调度器需要决定谁是下个幸运儿的时候,它就检查每个请求上标签。每个客户端都有自己的权重 \(w_i\) 。我们用权重的倒数就可以构成一个等差数列,
在服务端,当请求到达的时候,就根据请求所属的客户端为请求打上标签。同一客户端发来的请求构成了这个数列。权重越大客户端对应的序列分布越密集。下图中有蓝黄和绿三个客户端,它们的权重分别为 1/2,1/3 和 1/6。
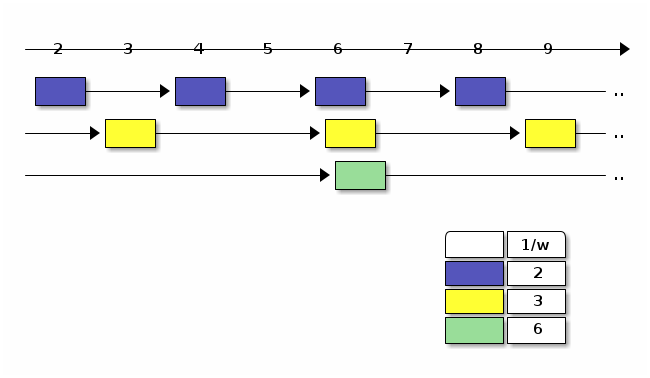
如果标签小于当前时间就按照先小后大的顺序依次处理,那么在单位时间里面,客户端得到处理的请求个数所占比例也就是它分到的权重。
我们还可以从完全公平调度(Complete Fairness Scheduling)算法的角度来进一步理解。CFS 的调度对象是进程。它按照 RUNNABLE 进程的虚拟时钟从小到大排序,时间靠前的进程先调度,靠后的后调度。每个进程都有自己的虚拟时钟。内核定期按照物理时钟的节拍推进所有的虚拟时钟。各进程时间流逝的速度是不一样的,优先级高的进程时钟就走得慢,低的走得快些。这样,CFS 就能直接调度排在最前面的进程。顺便说一下,Linux 中的 CFS 调度器是用红黑树来管理这些 RUNNABLE 进程的,树的键就是虚拟时钟的值。
另外,由于时间早的会先调度,所以如果谁的时钟停摆很久,如果它的标签一开始就比它优先级高的其他人低好多,那么一旦开始发送请求,接下来就会因为自己的时钟读数比其他人都小而连续抢占资源,导致发生饥饿。因此 mClock 论文里面说的 global virtual time 或者 virtual time 也就是为了解决这个问题。全局时钟要求所有的客户端时钟不管客户端是不是正在发出请求,都不断地往前推进。确保不会有人中途加入,打乱其他人的步调。
mClock
mClock 把这个想法推而广之,既然我们要支持 reservation 和 limit,为什么不能用他们来计算 tag 呢?我想这也是 mClock 的名字的由来,multiple clocks。于是在处理每个请求的时候,都会给他们设定三个 tag:
-
\(\mathit{R_i}^{r}\)
-
\(\mathit{L_i}^{r}\)
-
\(\mathit{P_i}^{r}\)
其中,
-
R 代表 reservation
-
L 代表 limit
-
P 则是 priority, weight 或者是 proportional
以 \(\mathit{R_i}^{r}\) 为例,用下面的递推公式计算:
其中, \(\mathit{r_i}\) 就是第 i 个客户端的 reservation 值。相邻 tag 的距离就是 \(\frac{1}{r_i}\)。而 \(\mathit{t}\) 是当前的时间。
那么刚才说的 global virtual time 的问题怎么解决呢?因为新客户端的上一个标签无据可查,而且枚举 所有 的客户端,定时遍历每个人的时钟,挨个更新它们的三个 tag,对系统可能也是个负担。论文采取的办法是,把所有人的 P 和当前时间对齐。
写成 C++ 代码,可能就是这样:
void request_arrival(request_t r, time_t t, vm_t i)
{
if (vm[i].was_idle()) {
// tag adjustment
if (!P_tags.empty()) {
auto min_P_tag = std::min_element(std::begin(P_tags), std::end(P_tags));
for (auto& vm : active_vm) {
P_tags[vm.id] -= *min_P_tag - t;
}
}
}
// tag assignment
R_tags[i] = std::max(R_tags[i] + 1 / reservation[i], t);
L_tags[i] = std::max(L_tags[i] + 1 / limit[i], t);
P_tags[i] = std::max(P_tags[i] + 1 / weight[i], t);
schedule_request();
}为什么对 \(\mathit{P_i}^{r}\) 特殊处理呢?我们假设直接使用当前的时间作为新人或者刚开始 active 的客户端的 \(\mathit{P_i}^r\)。那么对其他客户端来说,它们发出第一个请求的时候,\(\mathit{P_i}^{r}\) 也是当前的系统时刻,但是当客户端持续地发出请求,随着时间推移,根据各自的权重不同,你我的时间开始差得越来越多,贫富差距慢慢显现。但是新来的客户端横空出现打破了这个均衡,它的 \(\mathit{P_i}^{r}\) 不是根据之前的 \(\mathit{P_i}^{r-1}\) 推算出来的,而是直接使用的当前时间。虽然它的优先级可能并不高,但是它在一段时间之内凭借它的暂时的“后发优势“,无缘无故地打败了很多甚至优先级比他更高的老前辈,直到它的权重慢慢地把一开始的 P 慢慢抵消,一切恢复正常。mClock 算法为了解决这个问题,转而以最新的系统时钟调整其他老革命的 P,让所有的 P 按照时间轴平移,令最小的 P 等于系统时间。这样新加入的 P 就不会干扰现有的秩序了。因为 P 标签有累计的效应,所以这里仅仅调整它。
有了三个 tag,那么到底以谁为准呢?调度器有两种决策模式,并根据当前情况在两者之间切换:
-
基于约束的决策:调度器先看看有没有人的 R 小于当前时间,要是有的话,就直接调度最小 R 的请求。一旦所有的 R tag 大于当前时间,就脱离基于约束的决策模式,进入基于权值的模式。
-
基于权值的决策:这时候所有人的 reservation 都已满足。调度器开始按照权重来分配资源。它先把资源用量还没有超过上限的人找出来,他们的 L 比当前时间小。然后从中找出 P 最小的。调度 \(vm_{i}\) 的请求的时候,除了让它的最前面的请求出列,还需要把 \(vm_{i}\) 其他还在队列里面的请求的 R 都减去 \(1/r_{i}\)。这样可以保持相邻 R 的差仍然是 \(1/r_{i}\)。否则,我们想象一下,如果一个客户端很长一段时间它的请求都是用基于权值的决策调度的,那么它的 R tag 就会非常大。一旦系统的资源吃紧,它会立即得不到应该有的 reservation。为什么?只是因为它一直因为权重得到了很多服务,但是这笔账不应该算在 reservation 头上。所以我们每次因为权重调度请求,都需要把这个客户端的还没调度的请求的 R tag 都往前移动一格。确保这个客户端的 reservation 不会受到影响。
mClock 为存储系统做的一些改进
突发情况
有些客户端可能会稳定地发送读写请求,但是也有那种平时不动声色,突然狮子大开口的角色。有时候请求会陡然增加,我们叫做 burst。比如说有的客户端每个晚上会为文件建立索引,但它白天却悄无声息,这时候我们希望感谢它之前高风亮节为大家节省资源,给它个行个方便,让它一开始的 \(\mathit{P_i}^{r}\) 小一些。
这个 \(\sigma_{i}\) 可以每个人都不一样,我们暂且把它叫做"先人后己奖励奖"吧,专门用来补偿把带宽让给别人的人,让他们在有急需的时候也能感受到 QoS 的温暖。论文后面也提到,如果这个奖金太高,会因为扰乱权重分配的决策,导致细水长流式的客户的高延迟。
读写有别
在存储系统里面,写的延迟往往比读请求要高。但是我们没办法取巧,把同一个客户端的请求乱序执行。比如,把读请求放到写请求之前乱序执行未导致读到不一致的数据。
大小有别
IO 请求有的大,有的小,不能等同视之。因为我们不追求绝对的延迟数值,比如说一个 4k 的读请求需要多少毫秒。我们希望得到的是一个比例,即大小为 S 的 IO 请求产生的延迟相当于多少个单位大小的 IO 请求。
论文大概计算了一下,其中 \(T_{m}\) 表示机械动作产生的延迟,假设每次随机读写都要求机械磁盘的悬臂产生移动到对应的磁道,磁盘都需要转动到需要读写的扇区。而 \(B_{peak}\) 是磁盘最高的读写速度。
dmClock
分布式的场景下,每个服务器需要了解两件事情
-
你从所有服务器总共获得了多少服务
-
其中,你通过 reservation 获得了多少服务
为了让服务器知道客户端的服务情况,客户端在发送请求的时候也会顺带着发送
-
\(\rho_{i}\) 最近请求到当前请求之间,因为基于约束的决策获得的服务数量。其实也就是因为 reservation 获得的服务数量。
-
\(\delta_{i}\) 最近请求到当前请求之间,获得了多少服务。
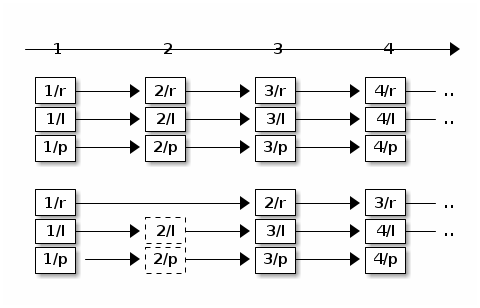
下面是之前介绍的单机版递推公式:
可以发现,我们把 1 换成了 \(\rho_i\)。这个思路和之前是一脉相承的。有点像一个大型的合作性的公寓,每家都有个户主负责向提供交各种费用水费、电费、煤气费。但是户主们并不是各自为政,只要交的总金额足够支付整个公寓的账单就行,当然,家里面有的时候没有流动资金,所以紧张的话,有的人可以少交有的人也可以多交。但是户主和户主之前缺少有效的沟通方式,好在自来水公司它们都有明细账,所以户主在缴费的时候可以查看之前的账目。这里户主就像分布式系统里面提供服务的节点,各项费用的账单就像不同性质的客户请求。缴费的过程就是处理客户请求。借用刚才的示意图,我们以 100 块钱为单位,如果公寓上个月加起来交了 200 块钱电费,那么电力公司这次就应该把付账的进度条往前推进 2 个单位。所以图里面的有两个请求就用虚线表示了,它们代表在其他服务器处理过的请求。
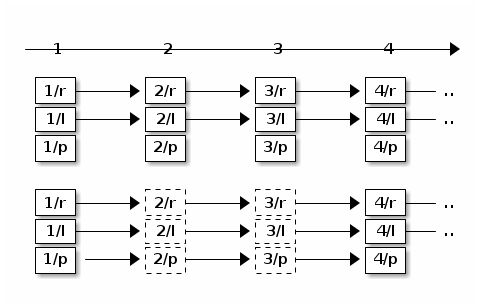
公式里的 \(\rho_{i}\) 和 \(\delta_{i}\) 就是这里的"2"。这两个系数表示因为不同原因,自从上次从这个服务器处理请求,这个客户端一共从不同服务器获得了多少服务。很明显,\(\delta_{i}\) 应该总是大于等于 \(\rho_{i}\)。如果是单机的话,两个参数就退化成 1 了。
dmClock 在 Ceph 中的应用
因为 dmClock 是一个通用的算法,Ceph 并没有把直接集成在自己的 repo 里面,而是单独实现了高度模板化的 dmClock 库。这样其他应用也能使用它。dmClock 库基本忠实地实现了论文中的算法。开始之前,请大家注意,目前 Ceph 正在使用的并不是 dmClock 而是 mClock。
OSD 中的 QoS
OSD
需要处理多种请求,有的请求优先级比较低,比如后台的数据恢复,有的请求优先级比较高,比如说前台客户发来的读写请求。而
OSD 的处理能力有限,又希望有一定的 QoS
能力。就需要设计一个能兼顾不同优先级需求的调度器。我们把不同类型的请求看成不同的客户端,在
OpSchedulerItem 就定义了下面几种请求
-
client_op -
peering_event -
bg_snaptrim -
bg_recovery -
bg_scrub -
bg_pg_delete
以
bg
开头的请求都是后台的请求,它们保证系统的正常运行,但是优先级相对于前面两类请求就要低一些。而且,每个
OpSchedulerItem 都有自己的 priority 和
cost。所以调度器调度的对象就是
OpSchedulerItem
了。但是可能和大家猜测的不同,OSD 用来实现 QoS
的调度器却不是全局唯一的。它是
OSDShard 的成员变量。而
OSDShard 则是 OSD
的执行单位,它维护着一个队列。队列里面的元素就是被安排执行的请求。每个
shard 都负责一个或者多个
PG,每当有请求到达,都会用请求对应的 PG 作为 key 找到对应的
shard,让 shard
决定什么时候执行它。而这个决定就是由调度器做出的。所以有多少个
OSDShard
就有多少个调度器,它们分别为各自负责的一组 PG 调度请求。
我们有两个调度器
ClassedOpQueueScheduler
这个调度器很像 Low-latency queuing。它基于 WeightedPriorityQueue 实现,简称 WPQ。它的设计和大家熟知的 Weighted Fair Queueing 调度器很像。WPQ 维护着多个子队列,每个队列有自己的优先级。在调度的时候,队列按照优先级享有对应的权重,被选中的机会就是权重的大小。选好队列之后,再随机选择队列里面的请求。请求的 cost 越低,被选中的可能性越大。但是这个设计可能太“公平“了,但是对于低延迟的请求响应可能就不够及时。所以除了这个为普通优先级服务的加权公平队列之外,调度器还另外定义了一个单独的 WPQ,为低延迟的应用提供了严格优先级的服务。只有严格优先级队列里面的请求处理完了,它才会开始检查普通优先级的队列。
mClockScheduler
前面提到一个 OSD
有多个调度器,但是它们共享除了系统线程之外所有的资源,而且缺少有效的隔离措施。所以在设置预留值的时候是按照假设的介质提供最大带宽按照
shard 的数量平均下来计算的。和
ClassedOpQueueScheduler 类似,mClockScheduler
定义了一个 "immediate"
队列,它提供为高优先级的客户端先进先出的服务。只有这个队列没有元素的情况下,才会转用基于
mClock 的队列。为了方便测试,现在预定义了三种 QoS
模式,分别为三大类请求设置了对应的参数:
|
QoS模式 |
服务类型 |
预留 |
权重 |
上限 |
|
偏重客户性能 |
client |
50% |
2 |
inf |
|
recovery |
25% |
1 |
100% |
|
|
best effort |
25% |
2 |
inf |
|
|
均衡型 |
client |
40% |
1 |
100% |
|
recovery |
40% |
1 |
150% |
|
|
best effort |
20% |
2 |
inf |
|
|
集中精力 recovery 型 |
client |
30% |
1 |
80% |
|
recovery |
60% |
2 |
200% |
|
|
best effort |
1% |
1 |
inf |
mClockScheduler 中,很重要的一个函数是
mClockScheduler::ClientRegistry::get_info(),它负责把请求按照他们的
get_scheduler_class()
分门别类,套用上面配置的 res,
wgt 和 lim 参数。
-
MOSDOp:
-
CEPH_MSG_OSD_OP或者CEPH_MSG_OSD_BACKOFF: client。这一类所有的请求都用default_external_client_info -
其他: immediate
-
-
PG 操作
-
pg delete: background_best_effort
-
pg scrub: background_best_effort
-
pg snaptrim: background_best_effort
-
pg peering: immediate
-
pg recovery:
-
高优先级的就是: immediate
-
低优先级就是: background_recovery
-
-