最近为了支持多单词的准确搜索,把 Ceph 的文档编译和 host 转移到了 Read the Docs 上。但是还有一些问题。
Ceph 里的 API 文档
Ceph 用 Sphinx 编译文档。它作为一个平台提供 librados,让大家可以用它写程序。librados 有各种语言的绑定,其中一些有对应的文档:
-
C: 用 Breathe 的 autodoxygenfile directive
-
C++: 还没有加上去。不过我觉得用 Breathe 和 Doxygen 的组合应该就够了
-
Python: Sphinx 有内置的支持,即 sphinx.ext.autodoc 扩展。我们主要用它的
automethoddirective -
OpenAPI: 用 sphinxcontrib.openapi 提供的
openapidirective
Sphinx 的搜索
Sphinx 内置有搜索功能,它也支持多词搜索,但是通常我们希望搜索 source code 的话,Sphinx 会返回所有包含 source code 的文档,即使文档里面出现的是 "code source" 或者 "source of code"。换言之,它不是我们习惯上的多词搜索。这个问题其他开发者也碰到了,在 Sphinx 上有相关的 issue。我研究了一下,这个问题在于 Sphinx 搜索的实现比较直接。它分这么几步
所以可以想见,如果我们搜索 "fuse support" 想看看 Ceph 对 FUSE 的支持,它会返回 mount.fuse.ceph 的 manpage。这虽然也不算离谱,但是里面出现的 support 是这么一句话
The old format /etc/fstab entries are also supported:
通篇没有出现 "fuse support" 这个序列。搜索返回了 32 篇文章,后 31 篇 文章被检索到的关键字就是 unsupported。这个很可能不是我们想要的。而 RTD 的多词搜索的结果要好很多。对于不挑剔的读者基本上够用了。
那为什么要纠结多词搜索呢?因为我们很多命令是多个单词构成的。比如说
ceph df要是用户想搜索 "ceph df",多词搜索要是能精确匹配,问题不就能解决了吗?那有没有其他办法呢?
-
google 的站内搜索。但是 google 是一个商业公司。有的人可能会浑身不自在,如果他用一个广告公司的搜索。虽然在这个世界上,我们和商业公司有千丝万缕的联系,但是,哎。让我们留一点理想主义的念想吧。
-
直接用 Read the Docs 的一揽子方案。它和 travis 这些服务很像,不仅内置了 CI 的功能,也能帮着 host 这些静态页面。对我们很合适。但是它的 build 流程是很死的。看看它的配置文件就知道了。这是为一个纯 Python 项目度身定制的。我们后文分析这个限制的影响。
-
其他 sphinx search plugin。找了一圈,没有不收费的。功能比较好的也需要自己搭建 Elasticsearch。RTD 开源了他们的方案。但是一想到要挠我们实验室小哥的门,我就知趣地把爪子收起来了。
假的 librados
Read the Docs 的搜索不错,但是它的限制也很明显。
-
只能通过
requirements.txt安装第三方依赖。那么requirements.txt到底是啥呢?它是 pip 用来给pip install传参数的。 文档说得明白。 -
也可以用 setuptools 或者 pip 安装源码里面的 Python 项目。
-
没有预处理阶段。
pip装好了,直接就是sphinx-build。
我们回到各种语言的绑定:
-
C: Breathe 其实本身并不能解析 C 代码里面的注释,也不能理解头文件。它事实上担当的角色是 Doxygen 产生的 XML 文件到 Sphinx 中间的桥梁。但是如果这些 XML 不存在,巧妇难为无米之炊。所以它会调用用 Doxygen 预处理一下指定的文件。但是问题来了,doxygen 怎么安装呢?它是一个 C++ 的项目。
-
Python:
automethod读取制定方法的 docstring,产生 Sphinx 的文档。最近一部分代码用上了 PEP484 风格的标注,所以我们也用 sphinx_autodoc_typehints 来把这些标注变成 Sphinx 文档。这两种办法都要求 Sphinx 的 Python 环境能访问被处理的 Python 扩展 (模块)。 -
OpenAPI:
openapi读取的是一个 yaml 文件。我们目前解决这个问题的办法是直接把这个文件放到了 repo 里面。但是大家都知道这个 yaml 文件其实是从代码产生的。把预处理的结果放到 repo 里面显然不是一个最好的方案,在现阶段这是一个折中。
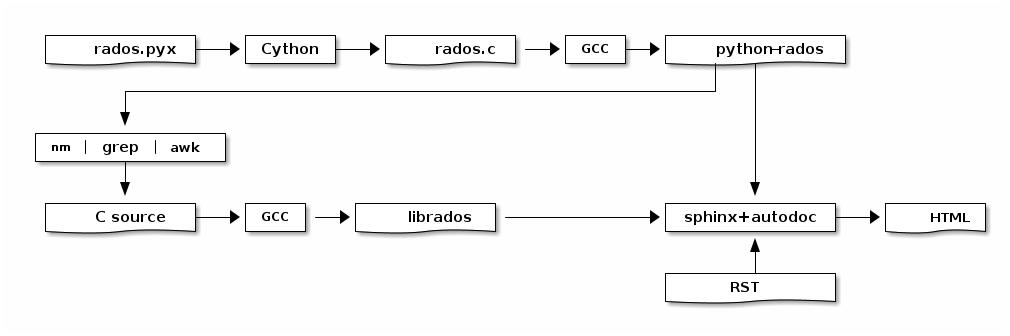
但是对于 Python API 来说,以 python-rados 为例,它是用 Cython 编写的 Python 扩展,它的底层则是 librados C API。我们编译文档的时候其实并不需要一个功能上完备的 librados,我们只需要让 sphinx 能导入 python-rados 就行了。sphinx 并不会真正运行 python-rados 的函数,它只会读取代码里面的元数据。所以 Ceph 里面用了一个比较取巧的方法。
-
为
lib/librados.so建立一个空链接,指向lib/librados.so.1 -
用 GCC 编译一个空的
lib/librados.so.1 -
用
pip安装 python-rados,pip 会自动执行setup.py脚本,后者会-
调用 Cython 编译对应的 rados.pyx,生成 C 代码,然后
-
GCC 继续用指定源代码里的头文件目录,刚才生成的空动态链接库,生成 rados 的 Python 扩展。
-
-
至此,rados 的 python 扩展编译好了。但是它链接的
librados.so只是个空壳子。如果有人希望import rados,一定会出错。因为那些符号都不存在呢。所以我们用nm分析这个 Python extension,找出它引用的所有符号,看看它有没有 librados API 的前缀。把这些符号,其实也是函数,统一写成void func(void) {}的样子,用管道交给 GCC 生成新的lib/librados.so.1。虽然它是假的,但是至少import的时候就不会出错了。
OpenAPI 文档的 yaml
文件的产生过程要简单很多,但是也需要使用我们自己编写的 python
脚本。但是 RTD 的
requirements.txt 没法实现这么复杂的预处理逻辑。
方案
Sphinx 能看见的预处理结果
为了能有一个 librados,我们可以在 PyPI 注册一个项目,让 Ceph 发布新版本的时候也更新它。同时,我们的文档编译流程也能直接从 PyPI 安装 python-rados。openapi.yaml 其实也可以放在这里面。具体说就是
-
注册 python-rados 项目。其他 Python 绑定也同理,比如 cephfs、rgw、rbd。
-
一旦修改任何 Python 绑定的 pyx,就需要发布一个新版。
-
让
ceph/admin/doc-read-the-docs.txt安装 python-rados, python-cephfs 等。
加入 stub 函数
在编译文档的时候,在
rados.pyx 中实现所有使用到的 C
函数。不过需要注意,这些函数也应该暴露出来给 python-cephfs
它们用。当然,只有在编译文档的时候才这么做。
浏览器能看到的
另外一个办法就是保留我们的 CI 流程,让它编译 API 相关的文档,然后让 RTD 的文档引用我们自己编译的文档。这需要
-
新建一个域名,专门用来保存 API 文档。题外话,它也可以用来保存 CI 产生的文档。
-
修改文档里面所有引用 API 文档的超链接,加入条件:
-
如果是 RTD 编译的话,就链接到刚才的域名
-
其他情况,就使用相对路径
-
后记
最后采用的是 stub 函数的方案。毕竟用 Cython 写个假的实现相对比较容易。同时,因为我们有很多 tell 命令,它们中有的是 C 实现的,有的是 Python 实现的。前者有固定格式的头文件来描述命令的参数,后者是用 type annotation 来标记参数类型。之前为了产生对应的文档,我们有专门的 Python 脚本。但是因为 Read the Docs 不支持这样的流程。所以为了能从 C 代码和 Python 代码生成文档,专门写了一个 sphinx 扩展。好在 sphinx 允许在扩展里面直接插入 reStructuredText 风格的 markup,这样搭配 Jinja 就方便多了。有点 PHP 的感觉,吼吼。