乱序和并发的问题无处不在,Ceph 里面也是这样。
RADOS 是 Ceph 的基础。而它在不同的上下文中有不同的含义
-
集群。比如说数据保存在 RADOS 集群里。
-
API。比如说,大家提到 librados,可能就是说用来访问 RADOS 集群的 C API。
-
RADOS 协议。librados 客户端要和集群通信,就基于这个协议。它包含着身份验证,鉴权,控制面的操作,以及 I/O,等等。
-
一个叫做
rados命令行工具。它可以说是 Ceph 的瑞士军刀。
这次我们从协议出发,讨论一下 OSD 对读写顺序的处理。它和前面的 多核和顺序 提到的乱序访问内存的问题非常相似。
librados 的访问顺序
客户端如果要访问集群中的数据,就需要向相关的 OSD 发送
MOSDOp 请求,OSD 则会用
MOSDOpReply 进行回应。它们两个是 RADOS
协议用来传输数据的很重要的消息类型。每个
MOSDOp 都包含
-
指定要访问的
hobject_t。它包含 pool ,对象的名字,对象的 snapid。 -
一系列
OSDOp,这些 op 就像是一系列指令,不过它们的操作的对象是同一个。要是有写操作,那么写入的数据也放在这个MOSDOp里面,按照先后顺序,放在同一个 payload 里面,解码的时候分给各自的 op。
librados 为客户端提供了两种调用方式
-
同步调用。
-
异步调用。
其中,同步调用很好理解。客户端在发送完请求之后,就开始等待,直到收到
OSD
的回应。但是如果客户端选择使用异步调用的话,它就可以同时发送多个
MOSDOp,而不用等待之前的请求返回。从 OSD
的角度来看,它有机会在同一时刻看到同一客户端先后发来的多个请求。不管如何,OSD
都有义务顺序执行这些请求,让客户端收到
MOSDOpReply 的顺序和它当初发送对应
MOSDOp 的顺序一致。Ceph 有个专门的测试,叫做
ceph_test_rados。这个测试会检查客户端收到的回应的顺序是不是对应请求发出的顺序。换言之,如果某个客户端的请求序列是
-
req(write(offset=601750, len=535546, payload)) -
req(write(offset=1929910, len=271840, payload)) -
req(setxattr("header", payload), truncate(size)) -
req(read(offset=0, len=1))
那么,OSD 的返回序列也应该是
-
ack(write) -
ack(write) -
ack([setxattr,truncate]) -
ack(read)
虽然 Ceph 也可以不坚持顺序。我的理解是,sequential consistency 是便于客户端编程的一个模型,所以 Ceph 选择顺序返回是很自然的事情。后来想了一下,对于 RBD 来说,如果系统先发了一个写请求,然后再发一个读请求,那么我们一定要先完成写请求吗?答案是……哪有那么巧啊!"我们"在这里其实是某个特定的 OSD,这两个时间上相邻的请求,如果不是访问同一个对象,那么怎么会这么巧,这两个对象都被分配到同一个 OSD,而且先后被访问到。就好像你和大学室友在市郊的加油站排队的时候遇见了。如果是同一个对象,那么问题来了。RBD 的使用者为什么会有这种需求呢?先写一块数据,然后不等写完,开始读同一块数据,而且不关心这个读到的数据是不是之前写下去的。RBD 使用者一般来说 Linux 的本地文件系统,它们对一致性还是有要求的,所以一般不会忍受这种脏数据。所以,按照 RBD 的需求分析,这种 load-store 的乱序执行是没有意义的,而且是错误的。
OSD 里的内存屏障
在 OSD 的这一边,它可能会看到多个
MOSDOp
同时访问一个对象。这些请求可能来自同一客户端,也可能来自不同的客户端。在保证原子性的前提下,为了提高并发度,我们要区别对待这些
MOSDOp 对应的事务。事务可以分为三种:
-
只读。很明显这些事务不会改变对象本身,所以它们可以同时进行。
-
只写。提到并发写,有人可能会有点犹豫。不过请不用担心,
-
读然后写或者写然后读。
如果好几个连续的
MOSDOp
都只进行读操作,那么我们是可以同时处理它们的。只需要按照顺序把它们依次发送给
object store 就可以了。 我们把这叫做 pipelined read:
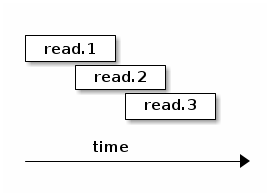
我们甚至可以把这些读请求一起发给下面的 object store,让它酌情同步处理。
和 pipelined write:
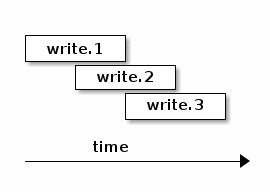
object store 自然会把它们序列化,依次处理。因为在 object store 里面也需要多个步骤才能完成一个写操作,所以把它当成一个流水线,提交多个操作更有利于提高并发。
但是如果某个请求里面既有写,又有读呢?感受一下:
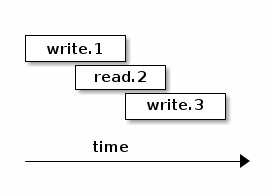
第二个事务中所有的请求都是读操作。在客户端发送消息的顺序上,这个只读事务排在第一个只写的事务之后。
TCP 保证了 OSD 也是按照发送的顺序收到这两个消息的,但是在 OSD
这边,如果不加以限制的话,或者允许乱序执行的话,就会出现
store-load 重排的情况。因为在 Ceph
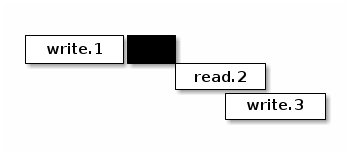
里面,读操作一般来说比写操作要快,因为读操作运气好的话,直接在缓存里面就能找到想要的数据,直接返回了。最不济,通过本机读几次磁盘,也能找到想要的数据。但是写操作不仅仅需要读本机磁盘,获得对象的元数据,还需要写本地磁盘,提交分布式事务,让其他副本也持久化,所以它的延迟比读请求是相对高一些的。如果我们放任自流,让两者的延迟决定谁先返回,不仅仅返回的顺序不对,返回的数据也可能是不正确的。如果我们希望实现一个严格的
sequential consistency 的系统,那么
read.2 就有义务体现
write.1 的结果。最简单的办法就是加上一个
sfence,保证 read.2 之前的写操作的事务提交完成。
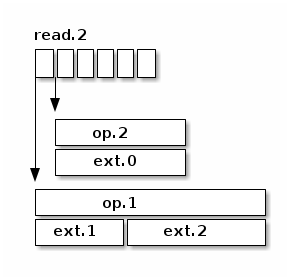
解决了 store-load 重排,那么 load-store 呢?我们允许在
read.2 仍然进行的时候,开始执行
write.3 吗?这取决于下面 object store
的处理顺序。我们假设这里使用的是 seastore。根据现在 seastore
的设计,要读取某个对象的指定 extent,需要
-
先根据索引 onode block 的 b+ 树,找到这个对象 onode 所在的 block
-
每个对象自己又有一个 b+ 树管理各自的 extent,如果运气好的话,b+ 树所有的叶子节点就内置在 onode 的 block 里面,但是如果这个对象比较大,或者 extent 的 b+ 树还没有来得及压缩,那么它就会有一些 extent 是需要再查询几个中间节点才能知道具体的逻辑地址的
-
其实上层根据逻辑地址访问下面的物理介质,都需要先把逻辑地址翻译成物理地址,这个过程也需要查索引,也就是要用 LBA 树来查找。而 LBA 树的节点也是不一定都在内存里面。
而 write.3 所对应的 extent
相关的索引信息说不定就在内存里面,可以很快的找到,从而开始写日志。同时呢,read.2
虽然身为读操作,有可能就没那么好运,需要读多次磁盘,才能找到对应的物理地址。所以我们无法保证读操作肯定是比写操作先完成的,即使读操作比写操作先开始。而且,这里的
read.2 和
write.3
都各自包含了多个操作,任何一个操作都会成为瓶颈。所以在某种极端情况下可能会是这样
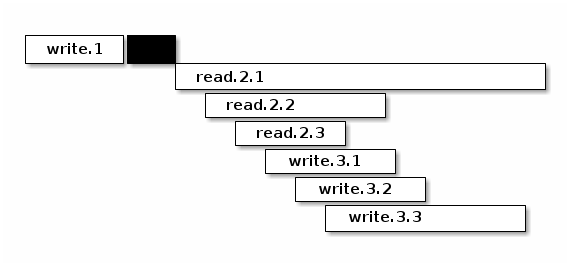
在这个捏造的例子里面,read.2.1
拖慢了整个事务的后腿,read.2 是在
write.3 之前开始的,但却在
write.3 之后完成。这对于期望 sequential
consistency
客户端显然无法接受。同时,我们还能想象一个更复杂的场景,因为每个读请求都会指定一个区间,告诉
OSD
自己希望读的偏移量和长度。但是这个区间可能会映射到对象的多个
extent,而每个 extent 的读延迟可能会不一样。倘若
read.2.1 指定的区间正好映射到某个 extent,而这个
extent 又正好和 write.3.1 所写的 extent
有重合呢?而且,请注意,例子里面
write.3 先结束,它的事务提交的时候,刷新了 OSD
内存里面所有相关的 extent 对应 block 的 cache。所以
read.2.1 有可能读到的是
write.3 所写的内容。更可怕的是,因为
read.2 读的是多个 extent,返回的 extent
中有的可能是新的,有的则是老的。所以这里还有一致性的问题。
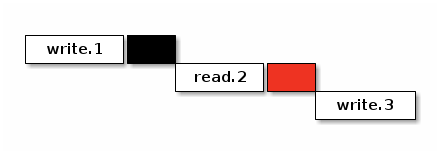
简单粗暴的办法就是在 read.2 之后直接加一个
lfence,确保所有的读请求都完成,防止乱序的发送,也避免读到不一致的数据。
对于 erasure coded pool 这个问题更复杂一些。如果对象保存在 erasure coded pool 里面,Ceph 在往里面写数据的时候,会
-
把数据拆开成
k等份 -
再根据选择的算法计算出
m个校验块 -
再把这些数据发往 m + k 个 OSD
倘若写操作的偏移量不是 m x chunk size 对齐的,那么这个写操作就会升级成 rmw (read modifiy write) 操作,因为它需要把自己少的那部分先读出来,解码,然后再和自己的没对齐的部分拼起来再重新拆分编码。
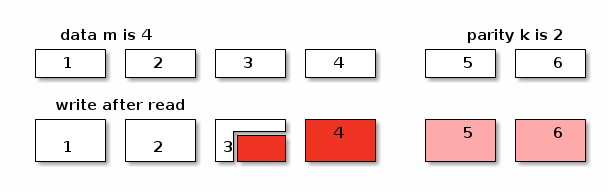
在上图中,在编码的时候产生了 6 块数据,其中 4 块是原始数据,2 块是校验数据。为了修改这个对象,而修改的位置正好落在了 3 里面,我们必须把整个数据都读进来,然后再把写请求的数据嫁接到 3 的对应位置,重新编码。得到被修改过的 3 和全新 4,以及融合了老数据和新数据的 5 和 6。正因为 erasure coded 的写操作事实上包含了
-
相邻区域的读操作
-
指定区域的写操作
所以它无法和其他的写操作在对象层面上同时进行。除非我们实现了更细粒度的访问隔离控制,确保事务的独立性。当然我们目前没有这么做并不意味着不可能,而是因为这样会比较复杂。因为每个写的事务都会涉及多个 extent。extent 可能会含有多个 stripe。两个写事务之间没有读写依赖的话,那么完全可以一起执行。也就是说,如果事务 A 不会写到事务 B 读取的数据,反之亦然,那么我们就可以认为两者是独立的。然是这需要在往下发送写请求之前,先把这些关系先分析清楚才能决定。这个可能太复杂了。而且得不偿失,以 RBD 为例,允许并发写一个 block 的请求的可能并不大。所以我们还是选择直接加 lfence。
在 crimson 里面使用了一个 shared_mutex 的变形
tri_mutex 来解决这个问题。常规的
shared_mutex
是一个读写锁,允许多个读者,或者单个写者。tri_mutex
借用了 mutex 的名字,其实它实现的是自动添加 sfence 和 lfence
的功能。它维护着一个等待者的队列,如果有新的请求进来,tri_mutex
就看看这个请求和当前的请求是不是能一起执行,如果不能的话,就进入队列,等到现在所有正在执行的请求结束之后才能开始;如果可以的话,就直接放行。从前面的讨论,可以知道我们有下面这个规则:
-
读操作可以和读操作并行
-
写操作可以和写操作并行
-
RMW 不能和任何操作并行