性能和易用性之间常常会有矛盾。
晚上到住处,有人可能会先放水,休息一下,简单吃点东西,然后呢,看看水温,差不多了洗个澡。用文艺的说法,这是生活的智慧。用体系结构的话说,这是乱序执行,使用了简单的调度算法。对单身汉来说,打乱计划,用不一样的顺序安排生活可以获得更高的效率。但是对多核程序来说,这其实不一定是好事。Jim Keller 打了个 比方,他说计算机是在顺序的手法说一个故事,书里面有很多段落,段落是由句子构成的。读者可以画一个示意图,看看哪些段落和句子读的时候可以打乱顺序,而不改变表达的意思。比如
He is tall and smart and …
可以改成
He is smart and tall and …
但是这个句子如果打乱顺序的话,"red" 修饰的对象可能就不对了
Tall man who is wearing a red shirt
句子里面的元素之间有依赖关系。
mutex 的问题
在多核环境下,要实现无锁编程或者尽量减少锁的使用,就不能用 mutex。其实,为了最大程度上优化,内核里的 mutex 在加锁的时候为了避免不必要的开销甚至分了 三种情况:
-
用
lock cmpxchg()指令,检查 mutex 的 owner 是否为空。 -
如果 mutex 的所有者正在运行,那么用 spin lock 等待它。
-
把希望得到锁的线程阻塞,挂到等待队列。等到锁释放的时候,再调度自己。
这个机制叫做 futex。在
Linux、NetBSD、FreeBSD、Windows 以及
Zicron
中都实现了它。在 FreeBSD 中甚至有明确的 spin/sleep mutex 和
spin mutex 的
概念。而在 Linux 中,futex 则是一个
系统调用。
不过,这些原语有两个问题
-
系统调用是个原罪。
-
鉴权。
-
切换栈。即使 x86 使用 syscall 来实现系统调用,因为内核的地址空间和用户态程序不同,进入内核要求修改段寄存器,相应的带来 TLB 的刷新。
-
缓存的刷新。
-
-
POSIX.1 要求 mutex 同步内存。
前者大家做了很多实验,说明不管如何系统调用都比
longjmp
的开销都要大很多。而今天我想把后者展开说一下。
内存一致性
首先,什么叫同步内存?在多核系统里面,每个核都有自己的一个小天地,为了加快对内存的访问,CPU 核在内存中间有多层的 cache。这个设计有点像现在大家说的朋友圈。根据一些权衡,这个朋友圈中的 cache 根据亲疏远近又分了三六九等,即 L1、L2 和 L3 缓存。通常每个核都有自己的 L1 cache,L1 其中又分数据 cache 和指令 cache。L2 不分这么细。L3 缓存由多个核共享。CPU 的片内总线设计很大程度就是各个核和片内缓存的关系网的拓扑。 和硬盘一样,cache 对内存的映射也是有最小单位的,硬盘的单位是 block,而 cache 的单位叫做 cache line。所以,从硬盘往内存读数据是以页为单位,通常大小是 4K。从内存往缓存读数据以 cache line 为单位,大小一般是 64 字节。另外,还有一种特殊的缓存叫 TLB,它是用来缓存线性地址到物理地址映射的页表。每个进程都有自己的地址空间,所以每个进程的 TLB 表项也各自不同。这里涉及内存的寻址、分配和管理,我们可以另外说。
既然是缓存,就会有缓存的一系列问题
-
替换策略。比如大家耳熟能详的 LRU。再啰嗦一句,替换的最小单位也是 cache line。
-
写策略。
-
write through 写数据的时候,数据不仅写进 cache,而且也同时刷新内存。
-
write back 写数据的时候,数据仅仅写到 cache 里面,把相应的 cache line 标记成 dirty。在真正需要刷内存的时候再把数据"`写回`"去,一旦内存和缓存同步,这个 cache line 又是 clean 得了。因为 write back 性能比较好,缓存通常用它。
-
-
一致性。既然每个核读写都是通过自己的 cache,而不是直接访问内存,那么怎么保证各个核看到的数据是一致的?
MESI
这里主要就写策略和一致性展开来说一下。为了解决一致性的问题,CPU 的设计者会用 MESI 的某种改进版来保证缓存之间的同步问题。
-
Modified 我的这份数据是被修改过的最新版。这个数据所在的 cache line 被标记成 dirty。这个状态要求其他人的状态是
I。别人想要读这个数据,必须等我把它写回内存。一旦写回去,状态成为S了。 -
Exclusive 我的这个 cache line 别人都没有缓存,所以如果修改它的话,不会产生不一致。
-
Shared 我的版本和别人的版本是一样的,我们的版本都是最新的。不过,我们都是"`读`"者,如果要写的话,得先获得排他锁。
-
Invalid 我的版本比较老了。对于一个缓存来说,一个 cache line 如果是
I的状态,那就相当于它不存在。要是内核希望读它的话,会得到一个 cache miss。
假设 core#0 想写
0x1347
地址,它写的不仅仅这个地址对应的内存空间,它写的是这个地址映射到的整个
cache line。
-
core#0告诉内存说,请把0x1347所在的 cache line 交给我。 -
内存说,好的,这里是
0x1347所在 cache line 的 64 字节数据。 -
core#0告诉其它核,你们的 cache 里要是有这个 cache line,立即把它作废掉。因为它的值就快过时了。 -
其它核听到这个消息纷纷回应
-
好的,我把那个 cache line 给作废了。或者干脆清除,或者把它标记成
I。 -
好的。虽然我这里没有那个 cache line。不过你可以放心了。
-
-
core#0找到 cache line 中对应0x1347的字节,改成自己想要的值,把那个 cache line 标记成M。 -
core#1想读0x1347,但是它对应的 cache line 是I状态。 -
core#1问内存,请把0x1347所在的 cache line 交给我。 -
core#0不得已,把那个 cache line 写回内存。core#1立即读到了最新的 cache line,这时他们缓存对应 cache line 的状态都改成了S。
硬件重排序
这带来了另外一个问题,MESI 协议里面有两种操作会比较慢。
其中,写一个 cache line 需要好几步。如果 cache line
不在本地缓存,或者是 I 状态。这就是个 cache
miss。那么这种情况下,还需要读内存。然后为了获得 cache line
的排他锁,还需要得到其它核的确认。要是
core#1 的缓存在收到 invalidate
消息的时候正在忙其它事情呢?这会
core#0
的写操作。更何况现代处理器的核那么多,core#0
的写操作的瓶颈之一是最慢的一个核对 invalidate
请求的回应。所以 core#0 的 invalidate
最好能立即返回。所以我们在每个核的缓存前面放一个
invalidation queue,让这个操作成为异步的。core#0
只要把消息放在队列里面,就可以继续执行下一条指令。等
core#1
的缓存忙完了手里的事情,就会检查它的队列更新对应 cache line
的状态。CPU
的设计者没有就此止步,因为只是读内存,往每家的队列里面投递消息也很耗时,core#0
的流水线还有余力做其他工作,它不希望因为这个 cache miss
就干等着。最好能并行地多做几件事情。所以我们在本地的核边上也加了一个队列,叫做
store buffer 或者 write buffer。把写操作扔到 store buffer
里面,就可以立即返回。而本地缓存一旦做完那些准备工作,它就会从
store buffer 里面拿到要修改的数据,更新自己的 cache
line。反之,要是等待本地缓存和其他各方把所有这些步骤完成再循规蹈矩往下执行下一条指令,就太慢了!
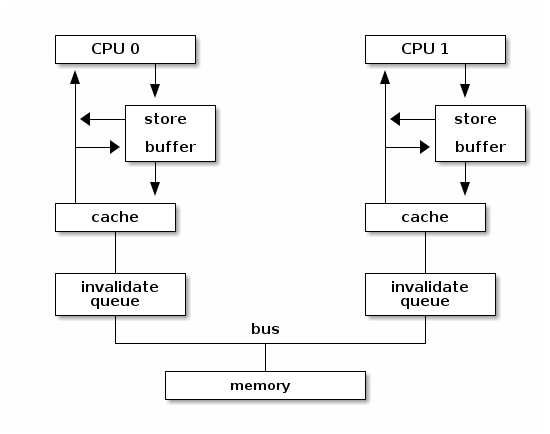
而读一个 cache line 也不容易。类似的,要是 cache miss 的话,那么当前核就会要求另外一个核把它的数据先刷到内存。这将引起一个内存事务。
但是这样引入了一个问题--------内存读写操作的乱序执行。这不仅让单核的顺序执行成为一个有前提的表象,更让多核的环境下的内存一致性和顺序执行更加错综复杂。对于特定的内核来说,可能会在一个写操作完成之前,就开始执行下一条指令。而对于其他内核来说,读指令可能会得到一个事实上过时 (invalid) 的数据。因为即使是写操作的发出者也还没有真正完成这个写操作,它只是把这个操作提交给了 store buffer。不过和其他内核相比,它是可以读到最新的数据的,在它执行读指令的时候,可以先检查 store buffer,如果 store buffer 里面没有对应的数据,再检查缓存。这个叫做 store buffer forwarding。因为它在当前核通过 buffer 把数据"转交"给将来要执行的读指令。这个设计保证了数据依赖和控制依赖,也就是单核上下一个操作的结果如果依赖上个操作的副作用,那么下个操作必须能看到上个操作的副作用。换句话说,如果从单核的角度出发,看不出这种"`依赖`"问题,那么 CPU 就认为它可以把读写操作重新排列,以此获得更高的并发度。另外,store buffer 的存在也催生了另外一些优化,如果有两个写操作修改的是连续的内存地址,在刷内存的时候,这两个写操作就可以合并成一个大的写操作,从而减轻内存总线的负担。这个技术叫做 write combining。 write combining buffer 就是处在 store buffer 和系统总线中间的地方。如果有往同一地址的写操作,那么时间顺序上后面操作就会覆盖前面的操作,这个技术叫 write collapsing。
这种读写指令的乱序执行破坏了严格意义上的顺序一致性。对很多人来说,如果你要的是咖啡加奶,那么做法应该是先加咖啡再加奶,但是对一个追求效率的人来说,可能就会应该先做咖啡,在咖啡机哼哧的时候,把奶加进去,等咖啡机好了,再把咖啡倒进去。不过要是有原教旨主义者看到这个顺序可能会很不高兴,他说顺序和比例一样重要!简单说,顺序对自己可能不那么重要,但是旁人可能会很在意。
但是甚至在不对齐写的情况下也会造成不一致的结果。说到 store buffer forwarding,之前 Linus 举了一个 例子。
假设有个系统有三个核,开始的时候
dword [mem] 的内容是
0。执行下面的程序
xor %eax, %eax
cmpxchl $0x01010101, (mem)movl $0x01010101, %eax
cmpxchl $0x02020202, (mem)movb $0x03, (mem),
movl (mem), reg
程序结束的时候,dword [mem] 可能是
0x02020203 ,但是有趣的是,这时第三个核上
reg 里面则会是 0x01010103。因为
MESI 协议保证了 cache coherency,dword [mem]
的值先后是 0 ->
0x01010101 -> 0x02020202 ->
0x02020203。因为最后一次第三个核的
mov 也获得了排他锁,然后把整个 cache line
刷到了内存里面。但是第三个核的寄存器为什么读到了一个奇怪的值。这个值甚至在
cache line 里面没有缓存过。原因是第三个核会这样解释:
movb $0x03, store_buffer[mem] ; 把 [mem] <- 0x03 的操作放到,store buffer,写操作比较慢。先继续执行读操作
movl (mem), reg ; 把 [mem] 的内容读出来
movb store_buffer[mem], reg ; 读操作也会查看一下 store_buffer,看看手里面最新的数据
所以第三个核寄存器中看到是一个脏数据。这个数据从来没有在内存中出现过。它有两个来源:高
24 位是第一个核写进去的,低 8 位是自己写的。而按照
cmpxch
的原子操作的语义,这个过程中是不可能有这样的不一致出现的。这也是为什么
amd64 不能保证非对齐写操作的原子性的原因。
话说回来,不仅仅是写数据上的核可能看到脏数据,也因为 store buffer 的存在,使得各个核看到的内存并不一样 (coherent)。如果某个核的对某个 cache line 的修改存在 store buffer 里面,那么这个 cache line 在其它核眼中则是旧的数据。另外,就算本地缓存检查了 store buffer,发送了 invalidate 消息给其他核。但是在其它核在检查 invalidation queue 之前,仍然会认为那个 cache line 是有效的。有人可能会说,其他内核可以在读缓存之前看看 invalidation queue 啊,可能是因为 invalidation queue 只是个 queue,内核在读缓存之前不会去检查 invalidation queue。所以如果多个内核共享一块内存,那么某个核上读写顺序重新排列会导致程序有不同的执行的结果。有的时候我们不在乎,但是有的时候这种不一致的结果是致命的。再举个例子,在餐馆吃饭。有的餐馆在顾客点菜之后会给一个电子闹钟,等闹钟响了,就可以去自助取餐。以此为背景,我们想象有两个核分别代表等餐的顾客老王 (wong) 和面馆老马 (mars):
bool placed_order = false;
bool beep = false;
char meal[128];
void wong() {
placed_order = true;
while (!beep);
claim(meal)
}
void mars() {
while (!placed_order);
cook(meal);
beep = true;
}
要是平时写这个程序,大家可能会很自然地用
atomic<bool> 来定义
placed_order 和 beep。但是既然
amd64 保证了
单字节数据访问的原子性
Cacheable, naturally-aligned single loads or stores of up to a quadword are atomic on any processor model, as are misaligned loads or stores of less than a quadword that are contained entirely within a naturally-aligned quadword.
所以
placed_order
的读写都是原子的。那么我们为什么还要用
atomic<bool> 呢?所以上面的代码就直接用
bool
了。接下来,我们在老王和兰州拉面的互动中加入 store
buffer,看看会发生什么:
-
老王来到面馆,大碗牛肉面!于是更新
placed_order。但是placed_order是在内存里面,写内存太慢了。先更新自己桌上的的 store buffer 吧。等会儿结账的时候再一起更新placed_order好了。 -
老王看着桌上的闹钟,焦急地等待。
beep啊,你怎么还是false呢?都十秒钟过去了。 -
面馆的马老板看着老王,这个人没有下单,眼神呆滞,从一坐下来就盯着桌上的闹钟不动。怕是昨晚加班到三点,还没缓过劲?
-
又过了十秒钟……两个人都隐约觉得有点不对,但是不知道出了什么问题。
对老王和老马来说,这都是个僵局。而这个僵局是 store-load 重排造成的。所以即使从单核的角度看,数据依赖和控制依赖是能够保证的,多核环境下也无法确保程序的"`顺序`"执行。换言之,cache conherence 不等于 sequential consistency。后者的语义需要引入更强约束。但是因为后者的约束太强了,我们在实际工作中往往会采用一些折中。
另外,如果文献中提到 load buffer 或者 load queue,它是用来保存读请求的。比如说,如果处理器预测某个写请求之后会读取地址 X,它会把这个请求放到 load buffer 里面。一个读请求的地址计算出来之后,这个请求也会保存在 load cache 里面。对于那个写请求,它在写内存之前则会检查 load buffer,如果发现命中的话,就会让读取 X 的请求返回写请求要写入的值。load buffer 可以让内存读取批次化,使得 cache miss 的处理更有效率。
一致性模型
不同体系结构在 consistency 这个问题上有着不同的答案,这些答案就是不同的一致性模型:
-
sequential consistency: 顺序一致,简称 SC。这是最死板的一致性模型。即使看上去没有危险,每个核也会以完全忠实原著的方式执行,除了缓存,不加入任何可能产生乱序的设计。所以 store buffer 和 invalidation queue 这种东西是禁止的。这种简单粗暴的限制对 CPU 的自尊心和性能是一种强烈的伤害。
-
weak consistency: 弱一致。在一定程度上允许重排序,受到 memory barrier 的约束。
-
relaxed consistency: 处理器完全可以乱来乱序。
大家对性能都有自己的坚持,没有一个有追求的处理器是顺序一致的。或者说,做到高性能的严格的顺序一致会非常困难。不过 amd64 是最接近的。它只会把代码里面的 store-load 顺序打乱,变成 load-store。像刚才老王吃面的例子里面,本来老王先点面,再看闹钟,被处理器一乱序,优化成了先看闹钟,再点面。完全乱了套。
除此之外,还有下面几种排列。对于它们,amd64 就完全按照脚本执行了。
-
store / store
-
load / store
-
load / load
在各种架构里面,amd64 是比较保守的。其他架构就比较放飞自我,比如对于 aarch64 中的 ARMv8-A 架构, 它的文档提到
The ARMv8 architecture employs a weakly-ordered model of memory. In general terms, this means that the order of memory accesses is not required to be the same as the program order for load and store operations. The processor is able to re-order memory read operations with respect to each other.
而 Alpha 处理器则是另外一个极端。有这么一个 例子
int x = 1;
int y = 0;
int* p = &x;
void p1() {
y = 1;
mb();
p = &y;
}
void p2() {
int i = *p;
}
在处理器两个核分头运行完这个程序,i 竟然可能是
0! 可以这样解释
-
p2开始前就缓存了y,它知道y的地址保存的值是0 -
p1执行y = 1,发了一个 invalidate 消息给p2,然后立即返回了。 -
p2收到了y的 invalidate 消息,但是它并不急着处理,人家前面又没有mb()催着,于是这个消息在 invalidation queue 里躺着。 -
p1这边因为 invalidate 消息立即返回,满足了mb()的要求,所以程序得以继续往下执行p = &y。 -
p2为了得到*p的值,先读取p。读p并不要求刷 invalidation queue,所以它得到了y的地址。 -
p2根据这个地址,索引到了自己的缓存。缓存里面有,为什么不用呢? -
p2把原来缓存的y的值0赋给了i。
这里,Alpha 没有根据数据依赖来刷 invalidation
queue,因为为了得到 *p 读了两次内存。分别是
-
mov p, %reg -
mov (%reg), reg
这里有一个数据依赖的关系,因为第二次的输入是第一次的输出。本来很明显,最后
reg
的值至少应该是一致的。也就是说,不会出现历史上
*p
从来没有过的值。就像这个夏天你一直喝啤酒,从没喝过汽水。但是年前和一个朋友吃饭的时候,他说你们七月份在日本玩儿的时候,一起还喝过可乐。这一定是个错觉。你会觉得他记错了,把你记成另外一个人了。并不是说你从没喝过汽水,你小时候还挺喜欢喝。而是你和这个朋友才认识一年,你这一年的确没喝过汽水啊。
不过这些选择并没有高下之分。如果只允许重排一两种读写序列,好处是程序员可以按照直觉编写多核程序,而不用太关心读写重排的问题。问题在于处理器的设计会有一些限制。要是需要同时有高并发,和严格顺序,那么处理器就必须把这些读写序列组织成一个个内存事务,如果处理器发觉因为乱序执行破坏了事务,那么就必须把乱序执行的操作取消掉。这使得高性能的并行处理器的设计变得更复杂了。如果处理器遵循的内存模型允许处理器做很多类型的重排序,那么处理器的设计会有很高的自由度,能无所顾虑地应用一些提高并发性的技术,来提高访问内存的效率,比如
-
out-of-order issue
-
speculative read
-
write-combining
-
write-collasping
如果处理器不需要保证访存的顺序,在相同性能指标下,功耗也低一些。在保证数据依赖和控制依赖的前提下,处理器有最大的自由度重新排序读写指令的顺序。但是对程序员的要求就更高了。他们需要再需要顺序的地方安插一些指令,手动加入
memory barrier,让处理器在那些地方收敛一下。这些 memory
barrier 要求当前的内核把自己的 invalidation queue 里所有的
invalidate
消息都处理完毕,再处理读写请求。而程序员也可以帮助处理器做一些猜测,比如说
prefetch 和 clflush 具体影响处理器的
cache 行为。
memory barrier 和 lock
lfence, sfence,
mfence 是 SSE1/SSE2 指令集提供的指令:
The LFENCE, SFENCE, and MFENCE instructions are provided as dedicated read, write, and read/write barrier instructions (respectively). Serializing instructions, I/O instructions, and locked instructions (including the implicitly locked XCHG instruction) can also be used as read/write barriers.
- lfence
-
Load Fence: 即 read barrier。以
lfence调用的地方为界,定义了读操作的偏序集合。保证系统在执行到它的时候,把之前的所有 load 指令全部完成,同时,在其之后的所有 load 指令必须在其之后完成,不能调度到它的前面。换句话说,它要求刷 invalidation queue,这样当前核所有的 invalidate 的 cache line 都会被标记成I,因此,接下来对它们的读操作就会 cache miss,从而乖乖地从内存读取最新数据。 - sfence
-
Store Fence: 即 write barrier。以
mfence调用的地方为界,定义了写操作的偏序集合。保证系统在执行到它的时候,把之前的所有 store 指令全部完成,同时,在其之后的所有 store 指令必须在其之后完成,不能调度到它的前面。它要求刷 store buffer,这样当前核所有积攒的写操作都会发送到缓存,缓存刷新的时候会发送 invalidate 消息到其他核的缓存。sfence 是 SSE1 提供的指令。 - mfence
-
memory Fence: 即 read/write barrier。以
mfence调用为界,定义了读和写操作的偏序集合。确保系统在执行到它的时候,把之前的所有 store 和 load 指令悉数完成,同事,在其之后的所有 store 和 load 指令必须在其之后完成,不能调度到它的签名。也就是说,它会清空 store buffer 和 invalidation queue。 - lock
-
lock前缀:它本身不是指令。但是我们用它来修饰一些 read-modify-write 指令,确保它们是原子的。带有lock前缀的指令的效果和mfence相同。另外,文档告诉我们,xchg缺省带有lock属性,所以也可以作为 read/write barrier。所以在 内核里面有时会看到类似lock; addl $0, 0(%%esp)的代码,这里就是在加 memory barrier,同时检查0(%%esp)是否为零。
其实 x86 还有一些指令也有 memory barrier
的作用,但是它们本身有很强的副作用,比如
IRET
会改变处理器的控制流,所以一般来说,要控制内存访问的顺序还是用专门的
memory barrier 和 lock 指令比较容易驾驭。
所以有了 lfence 我们可以这么改
void p2() {
int* local_p = p;
lfence();
int i = *local_p;
}禁止处理器重排这两个 load 指令。
C++ 的一致性模型
C++ 程序员一般不会直接使用这些 memory barrier,它们太接近硬件,可移植性也很差。比如说 aarch64 上的 memory barrier 就叫别的 名字,功能也有些许的不同。所以 C++11 以及之后的标准规定了几种内存一致性模型,用更抽象的工具来解决这些问题。
在解释这些一致性模型之前,我们先回到刚才的面馆。假设老王顺利地下了单,老马也看到了老王的
placed_order
,开始做面条。但是问题来了,处理器不知道
beep 和
noodle
是有先后关系的,所以负责老马的那个核就自作主张,先刷新了
beep,而把 noodle 的写操作放在
store buffer 里面了。这是一种 store-store 重排,在 amd64
上不会发生,但是在其它架构是有可能的。
bool placed_order = false;
bool beep = false;
uint64_t noodle;
void wong() {
placed_order = true;
while (!beep);
consume(noodle);
}
void mars() {
while (!placed_order);
noodle = cook();
beep = true;
}这里有两种数据
-
被保护的数据
noodle -
用来表示
noodle状态的标志 —beep
这有点像使用 mutex 的情况。mutex 一般用来保护共享的数据,它自己则是有明确的状态的,即 mutex 当前的所有者。在这里也是如此,
- 老王
-
通过读取
beep的状态,获取锁,一旦beep告诉他,“可以通过”,那么他就可以放心访问被保护的noodle。这个过程叫做 acquire。 老马 开始的时候,老马其实已经是锁的所有者了。正是因为这样,他才得以放心地煮面,修改noodle。一旦完成了修改,他就可以通过修改beep的值来放弃锁。告诉别人,你们看到beep没有,它现在是响着的,可以来访问这个noodle了!这个过程叫做 release。
所以,为了避免 store-store 重排,我们用 release-acquire 语义改进了实现:
bool placed_order = false;
atomic<bool> beep = false;
uint64_t noodle;
void wong() {
placed_order = true;
while (!beep.load(std::memory_order_acquire));
consume(noodle);
}
void mars() {
while (!placed_order);
noodle = cook();
beep.store(true, std::memory_order_release);
}这里除了避免 store-store 重排,其实还确保 load-load 的顺序:
-
beep.store(true, std::memory_order_release)确保noodle = cook()产生的读写操作不会被放到beep.store()后面去。你想想,beep一响,就像泼出去的水,如果这时候告诉顾客,我还在擀面,那不是很让人恼火?所以我们一定要保证beep.store()之前事情不会拖到后面去。 -
beep.load(std::memory_order_acquire)确保consume(noodle)产生的读写操作不会放到beep.load()之前。否则就会出现老王在beep响之前,就直接去拿面的情况。让正在擀面的老马措手不及。
我们再回到 load-store 的问题。这个问题其实很难用
release-acquire 的模型描述,因为
placed_order
不是用来保护一个共享的数据的,或者说它本身就是一个共享的标记。在老王下单之前,他没有加老马家拉面的微信号,也没有填写老马搞的调查问卷。不过这个问题可以这么思考,placed_order
应该在老马看到它之后重新设置成
false,这样老马再次看到它的时候就不会以为老王又要了一碗面了。老王这边其实也有类似的问题,和他一起去吃面的老李也会改
placed_order,要是两个人都把
placed_order 改成了
true,那么老马做的下一碗面到底归谁呢?所以程序应该这么改:
bool placed_order = false;
atomic<bool> beep{false};
uint64_t noodle;
void wong() {
while (placed_order);
placed_order = true;
while (!beep.load(std::memory_order_acquire));
consume(noodle);
}
void mars() {
while (!placed_order);
placed_order = false;
noodle = cook();
beep.store(true, std::memory_order_release);
}这样还是有问题,因为老李搞不好会中途插一脚
-
老王看到没人下单了,正准备把
placed_order改成true。他还没开始placed_order = true就开小差了,看着门外突如其来的暴雨,又陷入了沉思。 -
老李也注意到了,他立即把
placed_order改成了true。开始看着beep焦急地等待自己的大碗牛肉面。 -
老王回过神来,也把
placed_order改成了true。 -
两个人一起焦急地等待那碗面。
所以我们应该用原子操作来修改 placed_order,让
read-modify-write 一气呵成,用 compare-and-exchange 正合适:
atomic<bool> placed_order{false};
atomic<bool> beep{false};
uint64_t noodle;
void wong() {
bool expected = false;
while (!placed_order.compare_exchange_weak(expected, true,
std::memory_order_relaxed,
std::memory_order_relaxed));
while (!beep.load(std::memory_order_acquire));
consume(noodle);
}
void mars() {
bool expected = true;
while (!placed_order.compare_exchange_weak(expected, false,
std::memory_order_relaxed,
std::memory_order_relaxed));
noodle = cook();
beep.store(true, std::memory_order_release);
}在 amd64 上
bool expected = false;
while (!placed_order.compare_exchange_weak(expected, true,
std::memory_order_relaxed,
std::memory_order_relaxed));会被 GCC 翻译成
movb $0x0, -0x1(%rsp) ; expected = false
mov $0x1, %edx ; desired = true
retry:
movzbl -0x1(%rsp), %eax ; expected => %al
lock cmpxchg %dl, 0x2ee2(%rip)
je while_beep_load
mov %al, -0x1(%rsp) ; %al => expected
jmp retry
因为我们只需要原子操作, 所以这里只用了
std::memory_order_relaxed,它对内存的访问顺序没有限制。但是前面提到,xchg
缺省带有 lock 属性,而
lock 前缀的效果和
mfence 相同。所以用不着专门加入
mfence,我们也能要求处理器顺序访问内存了。否则的话,我们需要这么写
placed_order = true;
std::atomic_thread_fence(std::memory_order_seq_cst);
while (!beep);这样 GCC 会产生
movb $0x1,0x2ef2(%rip)
lock orq $0x0,(%rsp)
nopl 0x0(%rax)
retry:
movzbl 0x2ed9(%rip),%eax
test %al,%al
je retry
clang 则会用 mfence 代替
lock orq
指令。效果是一样的。根据查到的文献,两者的性能不分伯仲。
load 和 store 一般成对使用:
| load | store |
|---|---|
|
memory_order_seq_cst |
memory_order_seq_cst |
|
memory_order_acquire |
memory_order_release |
|
memory_order_consume |
memory_order_release |
|
memory_order_relaxed |
memory_order_relaxed |
在 x86 下:
| C++ | 汇编 |
|---|---|
|
load(relaxed) |
|
|
load(consume) |
|
|
load(acquire) |
|
|
load(seq_cst) |
|
|
store(relaxed) |
|
|
store(release) |
|
|
store(seq_cst) |
|
|
store(relaxed) |
|
|
store(relaxed) |
|
其中,load(seq_cst) 和
store(seq_cst) 也可以这么实现
| C++ | 汇编 |
|---|---|
|
load(seq_cst) |
|
|
store(seq_cst) |
|
刚才我们用了
-
memory_order_relaxed/memory_order_relaxed -
memory_order_acquire/memory_order_release
帮老王和老马摆脱了困境。如果要解决 Alpha 处理器的问题的话,可以
int x = 1;
int y = 0;
atomic<int*> p = &x;
void p1() {
y = 1;
p.store(&y, memory_order_release);
}
void p2() {
int i = *p.load(std::memory_order_consume);
}好在只有 Alpha 处理器这么粗犷,敢于无视数据依赖,用刚从内存里面读出来的数据作为地址,来索引缓存里面的老数据,得到指针指向的数值。其他体系架构都会重视数据依赖问题,在这个数据依赖链条上顺序执行。因为 amd64 不会重新排列 load-load,所以它天生对这个问题免疫。另外,C++17 说
memory_order_consume: a load operation performs a consume operation on the affected memory location. [ Note: Prefermemory_order_acquire, which provides stronger guarantees thanmemory order_consume. Implementations have found it infeasible to provide performance better than that ofmemory_order_acquire. Specification revisions are under consideration.
看起来要实现依赖链条的分析很麻烦,几家 C++
编译器都懒得矫情,干脆杀鸡用牛刀,所以性能没提高。标准也向现实低头,那么我们如果一定要把依赖关系写得明明白白,做好跨平台的工作,还是用
memory_order_acquire
吧。图个省事儿,图个放心。等到真的有要求再手写汇编。这背离了设计
memory_order_consume 的
初衷,但是也是现阶段比较实际的办法。
前面为了让程序更好懂,这些 memory barrier 都和一个
atomic<>
变量放在了一起了。毕竟活生生的变量对于描述程序的逻辑才是有意义的。memory
barrier 只是用来保证执行的顺序而已。它就像
xchg 的前缀一样。但是我们也可以直接加入 memory
barrier:atomic_thread_fence。前面如果不能用
CAS 的话,我们可能就只能用这一招了。
std::atomic_thread_fence(order)
这样直接的 memory barrier,能和
atomic<> ,也能和其他
atomic_thread_fence<>
一起使用。效果是相同的。
后记
Ceph 是个分布式的存储系统。它里面客户端访问的数据被叫做 object。我们用 PG 来对 object 分组,把属于同一个 PG 的 object 安排在集群里的一组磁盘上。每个磁盘上都有一个服务,叫 OSD,来管理这个磁盘,同时与集群还有客户端联系。所以客户端在访问自己读写的数据时,就会直接和负责存储的服务用 TCP 进行通讯。
一个客户端对 OSD 的读写是原子的,这个是底线。那么我们是不是也可以乱序执行客户端发过来的读写指令呢?如果客户端发过来三个消息
-
write(obj1, data), write_xattr(obj1, xattr), read(obj1), read(obj1)
-
read(obj2)
-
write(obj3), write_omap(obj3, omap)
这里还有一些背景,客户端和 OSD 之间是通过 Ceph 自定义的 RADOS
协议联系的。RADOS 协议中一来一回的叫做 message,而用来访问
object 的 message 叫做
MOSDOp。它可以包含一系列的读写访问,但是同一个
MOSDOp
中操作的对象只能是同一个。这很大程度上限制了一个 message
里请求的可能性。因为在执行绝大多数访问 object 的操作之前,OSD
都需要读取这个 object 的 OI,即 object
info,获取它的一些元数据,比如这个 object 的大小,版本,
快照信息。有的时候因为操作的 offset
越界,这类操作就被作为无效请求,给客户端返回个错误,或者干脆忽略这个无效的请求。但是不管如何,写请求一般来说仍然是比读请求慢的,对于多副本的数据池,我们要求这些副本是一致的。这里的一致性问题和内存一致性类似,其实也可以展开说我们留着以后聊。对于
erasure coded 的数据池,我们也要求 k+m
都落地了才能返回,这些都很花时间。
之前在 crimson 例会上,曾经和同事讨论过 Ceph
是不是能乱序访问,Sam 说 RBD
的访问模式基本不可能有这种情况。因为 librbd 客户端的一个
message 里不会同时出现对同一个 object
的读操作和写操作。是的。块设备的访问模式和内存是完全不一样的。就算使用
RBD 的操作系统或者应用程序把一块内存 mmap
到这个设备,也会把读写尽量 cache
在缓存或者内存里面,除非不得已,比如说上层一定要
fsync。但是即使这样,fsync 所对应的
MOSDOp 也不会包含对所涉及的 object 的读操作。
那么我们换个问题,有没有可能,或者说应不应该把对
obj1、obj2 和
obj3 的访问乱序执行呢?先假设这几个 object
都同属于一个 PG,毕竟两个连续的操作的 object 同属于一个 PG
的可能性很小。就像是学校里面上公共选修课,随机点名的时候,你和室友都被抽中一样。
我们从有没有可能开始吧。librados 提供了两种操作,一种是同步的,另一种是异步的。同步的操作执行完毕才能返回,也就是说如果这个函数返回了,那么就可以认为集群已经把请求里面的写操作作为一个事务写到磁盘上了。异步的函数调用直接返回,不等待执行的操作落地。另外调用方需要给异步调用一个回调函数,这样 librados 就知道这个操作完成的时候该怎么处理了。前者相当于天然的 sequential consistency。后者就给 OSD 以可乘之机,在保证操作原子性的前提下,有一定的自由度可以调度队列里面的操作。
在这个框架下,还有个很强的限制。Ceph 有个测试叫做
ceph_test_rados,它根据配置向集群发送一系列异步的读写操作,每组操作都有个单调递增的编号。异步操作完成的时候,根据这个操作的编号我们能知道它的返回是不是顺序的。如果不是顺序的,这个测试会失败。换句话说,这个测试要求
sequential
consistency。如果这个测试是合理的,或者即使不合理也是无法变动的,比如说更高层的客户端,比如说
qemu 的 RBD
插件把这个作为一个协定,并且依赖这个行为,那么我们就必须比
amd64 更自律才行。当然,我们也可以异步返回,然后再在 librados
这一层再让新的调用阻塞在老的调用上,使得它们的返回看上去像是顺序的。
为了满足 sequential consistency 的要求,我们有两个选择。
-
执行上的 sequential consistency。这很明显是最稳妥的办法。把罪恶扼杀在摇篮之中,通讯层甚至可以等 MOSDOp 完成之后再读取下一个 message,但是这和咸鱼完全同步有什么区别呢?客户端之所以选择异步操作就是希望更高的并发啊。当然,即便如此,异步的操作仍然是有意义的。异步往 OSD 发射指令,而在 OSD 上顺序执行可以避免网络上的延迟。
-
表现上的 sequential consistency。这个说法并不严谨,其实表现上的顺序一致也需要执行层面的支持。我们权且把第一个的选择作为最直接了当的、完全阻塞的实现吧。这个选择的执行需要更小心一些。因为执行层面上可能的乱序,我们可能需要考虑下面几种读写序列的乱序
-
store-store
-
写同一 object。倘若 object 没有支持快照,只要最终的结果和顺序执行的结果一样,即可以认为这两次操作是顺序的。况且要是能在 object store 层面上实现 write collapsing 或者 write combining,岂不是一桩美事?
-
写不同 object。回到老问题,这两个写操作是不是带有 acquire-release 语义?会不会有老马和老王的问题?
-
-
store-load
-
读写同一 object。和前文中讨论的 CPU 的读写指令不同,RADOS 里面 store 和 load 指令的操作数都是立即数。所以不存在读写数据本身的数据依赖的问题。但是如果读的 extent 和之前写的 extent 有重叠,那么我们就必须小心了,至少需要先把写指令下发到 object store,然后由 object store 把 cache 修改了,并标记成 dirty 才能算是这个操作提交完成。这样等到执行 load 指令的时候才能读到最新的数据。
-
-
load-store
-
load-load
-
十年前,用 mutex 和
condition_variable
就能解决很多多线程的问题。在今天,这些同步原语仍然很重要。但是如果我们对高并发有更高的追求,就需要更深入了解多核系统中的无锁编程,在体系结构上多理解一些
CPU 和内存的交互,这样对工作会更有帮助。